Disclaimer: All proprietary company data has been completely anonymized and replaced with randomly generated counterparts, to respect the stipulations outlined in my non-disclosure agreement
I had some downtime at work and I realized that I often use the same functions during data cleaning/modelling, such as removing non-numeric digits from a DataFrame column for phone numbers. However, I didn’t want to keep copying and pasting the same long list of functions into every Jupyter notebook I work in, so the prerequisite was that I needed to be able to pull from remote .py file which already contains all the functions.
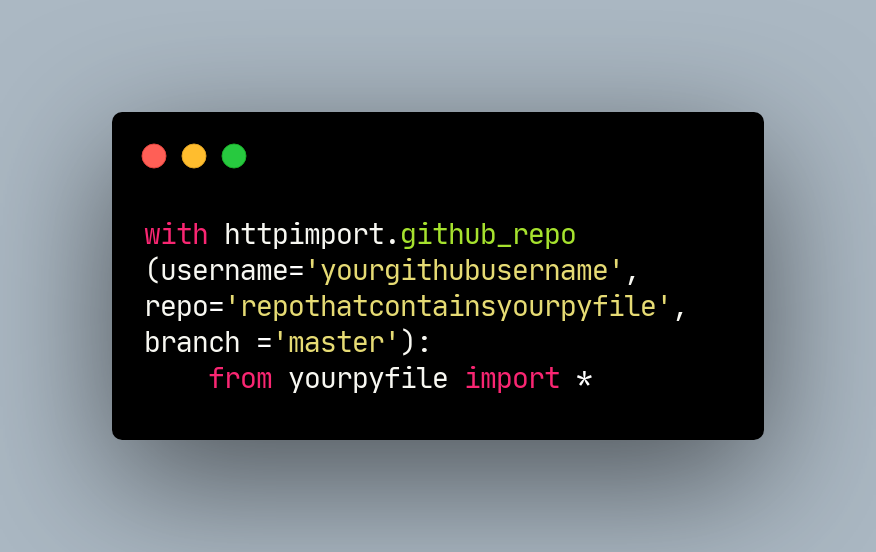
I looked into it and discovered a Python library called httpimport, which lets you run code that is stored in an external, web-facing .py file. There were a few options, but I created a github repository with a few functions that represented frequently used data transformations/cleaning tasks. You can also call the function to see the docstring before you use it, so you don’t have to check the repo if you forget. Another benefit of these remote functions is that it is possible for multiple members of a team to connect to it, making it possible to increase the efficiency of an entire team. Below are a few examples of these functions.
def phone_split(df, phone='phone', main='phone_main', ext='phone_ext'):
"""this function sanitizes phone numbers and appends any digits beyond 10 to a separate column"""
df[phone].replace(to_replace='[^0-9]+', value='', inplace=True, regex=True)
df[main] = df[phone].str[:10]
df[ext] = df[phone].str[11:]
df.drop(phone, axis=1, inplace=True)
def clean_col(name):
"""this function cleans clean column name and replaces empty spaces with underscores"""
return (
name.strip().lower().replace(" ", "_")
)
def unique_dataframe(df):
"""this function creates a dataframe with only unique values in each column"""
dict(zip([i for i in df.columns], [pd.DataFrame(df[i].unique(), columns=[i]) for i in df.columns]))
def trim_all_columns(df):
"""this function trims whitespaces from ends of each value across all series in dataframe"""
trim_strings = lambda x: x.strip() if isinstance(x, str) else x
return df.applymap(trim_strings)
def generate_temp_id(row, secondary_keys, drop_empty_values=True):
"""this function generates a temp_id by passing desired columns into secondary_keys value"""
sec_key_column_values = []
for key in secondary_keys:
val = str(row[key])
if drop_empty_values:
if val.strip() != '':
sec_key_column_values.append(val.strip())
else:
sec_key_column_values.append(val.strip())
temp_id = '-'.join(sec_key_column_values)
return temp_idBelow is an example of how you can use these functions
import pandas as pd
import numpy as np
import httpimport
with httpimport.github_repo(username=`yourgithubusername`, repo=`repothatcontainsyourpyfile`, branch =`master`):
from yourpyfile import *
print(phone_split.__doc__)
> `this function sanitizes phone numbers and appends any digits beyond 10 to a separate column`
phone_split(df_advisors)
df_advisors.head(30)
>| phone_main | phone_ext |
|---|---|
| 2029182132 | |
| 7014264205 | |
| 5822228140 | 313 |
| 2025327032 | |
| 2058721257 | 51 |
| 4015391828 |