Disclaimer: All proprietary company data has been completely anonymized and replaced with randomly generated counterparts, to respect the stipulations outlined in my non-disclosure agreement
I had many situations where I needed to add transactions to a client’s account in our database, using transactions they provided us in an .xlsx sheet. However, we already have their existing data in our database, with investor names matched to a certain id. Therefore, we need to avoid creating duplicate accounts/transactions when uploading this new data. The solution is to pull a list of investor names, their ids, and match it to the names in the new data to add the transactions to their respective accounts. Now obviously this method isn’t ideal, but most of the time the remaining unmatched investors are so few that it’s possible to manually sort through them.
I begin by importing the necessary libraries, establishing a connection to my local copy of the production database(although our MySQL database is on Azure, it’s much more complicated to connect with SSH tunnelling, and is potentially dangerous with Python), and read in the .xlsx sheet containing the new transactions to be uploaded.
We begin by importing libraries and establishing a connection to the local copy of the database
import numpy as np
import pandas as pd
import difflib
from datetime import datetime
from sqlalchemy import MetaData, create_engine
metadata = MetaData()
db_name='exemptedge_production'
engine=create_engine(f'mysql+pymysql://root@localhost:3306/{db_name}')
metadata.create_all(engine)
connection = engine.connect()
project_path = '/Users/oresttokovenko/Desktop/client_data/Client_1/Data/Aug_08_2021/'
df_v1 = pd.read_excel(f'{project_path}/Data_4Aug2021.xlsx',
sheet_name= 'Uploading Data')Next, I select the data I need to pull in regarding the specific client using a SQL query, the results of which then become a Pandas DataFrame
query = "SELECT id AS investor_id, account_type, LOWER(IF(account_type='investor', CONCAT(first_name, ' ', last_name), company_name)) AS account_holder_name FROM investors WHERE company_id = 153 AND active=1 AND deleted_at IS NULL"
live_investors_list_df = pd.read_sql_query(query, engine)
live_investors_list_df.shape()
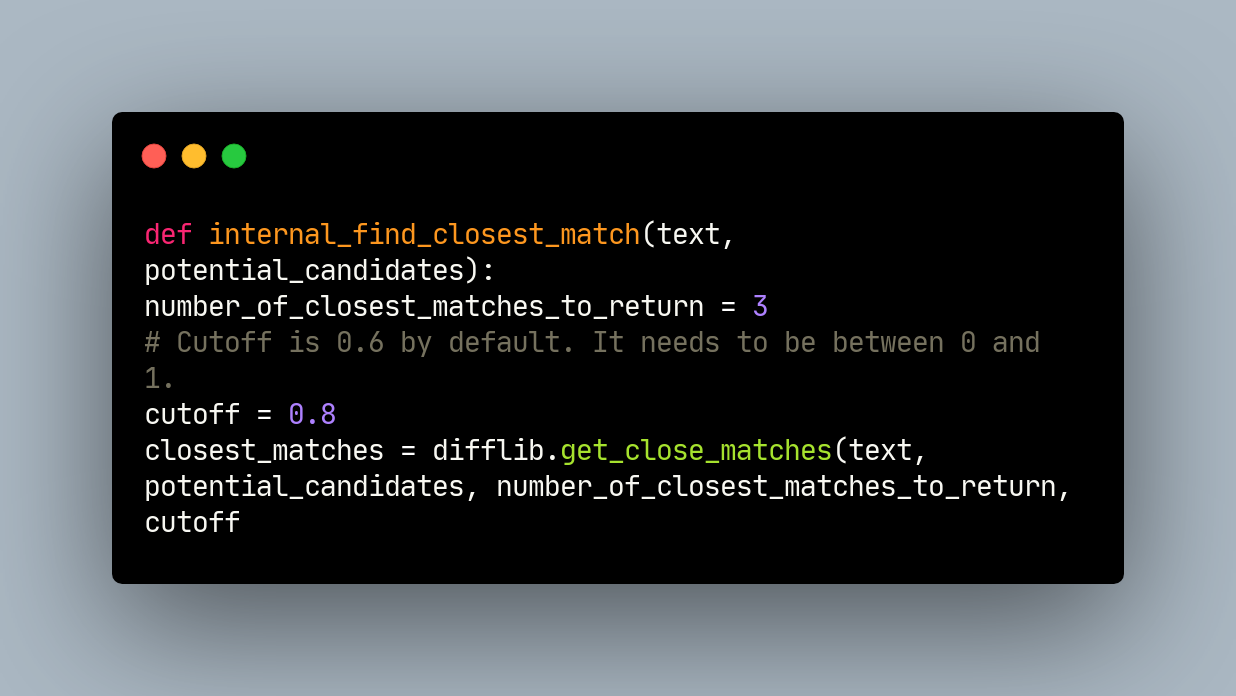
> (10208, 3)I write my matching functions using difflib, and since we’re dealing with financial data I set the cutoff to a high 8. We want high fidelity here.
def internal_find_closest_match(text, potential_candidates):
number_of_closest_matches_to_return = 3
# Cutoff is 0.6 by default. It needs to be between 0 and 1.
cutoff = 0.8
closest_matches = difflib.get_close_matches(
text, potential_candidates, number_of_closest_matches_to_return, cutoff
)
if len(closest_matches) > 0:
return closest_matches[0]
else:
return None
def df_find_closest_match(row, colname, potential_candidates):
text = row[colname]
text = text.strip()
closest_match = internal_find_closest_match(text, potential_candidates)
return closest_matchgetting a unique list of investors
list_of_people_to_look_up_in_db_df[
"name_lowercase"
] = df_v1["investor_name"].str.lower()
all_account_holder_names_in_live_db = live_investors_list_df[
"account_holder_name"
].unique()
all_account_holder_names_in_live_db
> array(['lela drake', 'mary taber', 'orlando ohara', ..., 'harvey prentice', 'albert hite', 'earl mcgraw'], dtype=object)Now that we have a unique array/list of investors that belong to this company, we can apply the function to receive the matched list, then merge the two dataframes
list_of_people_to_look_up_in_db_df[
"closest_account_holder_name_match"
] = list_of_people_to_look_up_in_db_df.apply(
df_find_closest_match,
axis=1,
colname="name_lowercase",
potential_candidates=all_account_holder_names_in_live_db,
)
live_investors_list_df.drop_duplicates(subset=['account_holder_name'], inplace=True)
df_v2 = pd.merge(
list_of_people_to_look_up_in_db_df,
live_investors_list_df,
left_on=["closest_account_holder_name_match"],
right_on=["account_holder_name"]
)The last step is to remove duplicates and checking to see if any matches failed
df_v2[df_v2.duplicated(subset='investor_name', keep=False)]
> (duplicates are present)
df_v2.drop_duplicates(subset=['investor_name'], inplace=True)
df_v2[
df_v2['closest_account_holder_name_match'].isnull()
]
> (empty table)Now that the names are matched, we can ensure that the investor_id matched up correctly too