Disclaimer: All proprietary company data has been completely anonymized and replaced with randomly generated counterparts, to respect the stipulations outlined in my non-disclosure agreement
As part of my role as a Data Analyst at Exempt Edge, I did a lot of data modelling and cleaning. Sometimes, we would receive up to fifty excel sheets from a client and would need to import that into our production database. To do this, I would use Pandas or sometimes Spark(for millions or rows) depending on the size. If the columns matched across all sheets I would then ensure all the files are in the same folder and the same file type (.xlsx in this case).
import glob
import pandas as pd
import numpy as np
# get file names
path =r'/Users/oresttokovenko/Desktop/client_data/client/Data/Aug_24_2021/Offerings'
filenames = glob.glob(path + "/*.xlsx")
filenames
> ['/Users/oresttokovenko/Desktop/client_data/client/Data/Aug_24_2021/Offerings/placeholder_1.xlsx',
'/Users/oresttokovenko/Desktop/client_data/client/Data/Aug_24_2021/Offerings/placeholder_2.xlsx',
'/Users/oresttokovenko/Desktop/client_data/client/Data/Aug_24_2021/Offerings/placeholder_3.xlsx',
'/Users/oresttokovenko/Desktop/client_data/client/Data/Aug_24_2021/Offerings/placeholder_4.xlsx',
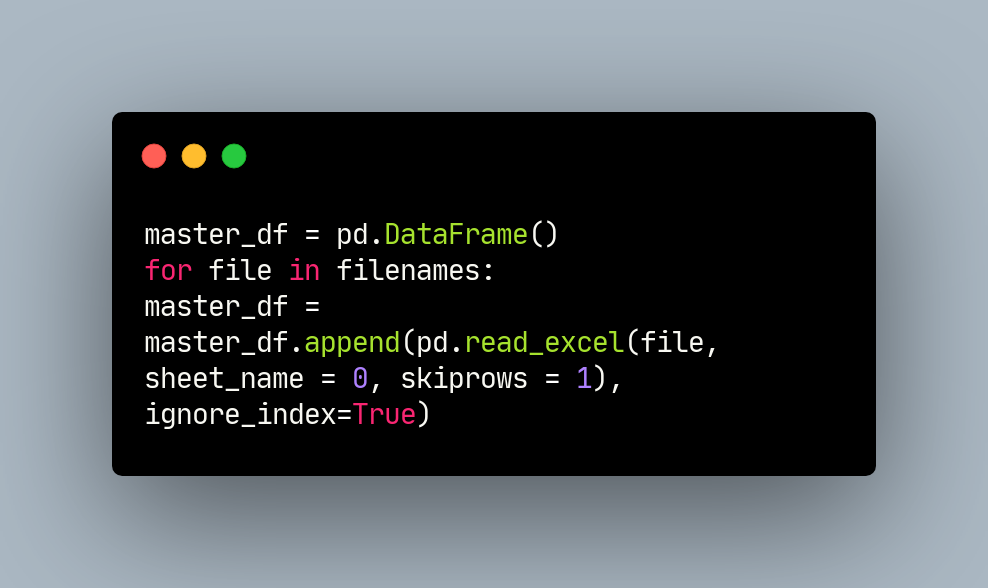
master_df = pd.DataFrame()
for file in filenames:
master_df = master_df.append(pd.read_excel(file, sheet_name = 0, skiprows = 1), ignore_index=True)
master_df.sample(20)If the relevant columns are not in the same position or do not match by name, that would require a more manual approach, reading in the columns from each sheet using usecols='A:T' or usecols='A,B,D,E', then concatenating them together using master_df = pd.concat([TFSA_df, RRSP_df, RESP_df, CASH_df])