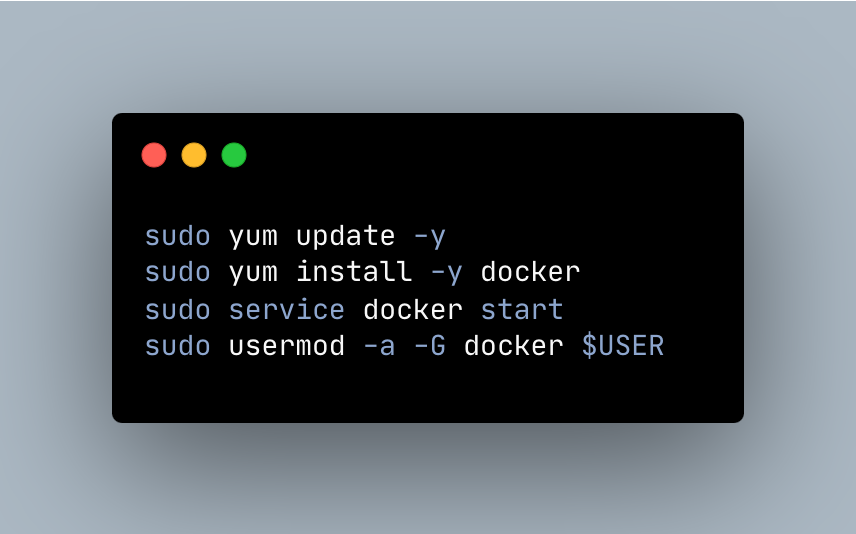
In the world of data engineering, tasks that seem simple on the surface can often be deceptively complex. Take for example the task of updating a new database with data from an old one, specifically ensuring that clients labeled as “inactive” in the old database are correctly listed as such in the new one. While it might seem like a simple SQL query would suffice, sometimes the reality is not so straightforward. In this blog post, we’ll explore a method for achieving this task using Python and Azure, and why it might be the simplest and most efficient approach in certain situations.
You might look at this task and think, I can write this in SQL, why use Python? Maybe append both tables from each database to a variable like @old_database and loop through them? The issue is, these databases are not in the same subnet in Azure, and a SQL query cannot connect to both of them simultaneously (at least not without extra work). I find this method simple and fast.
First, pull in the relevant tables from both databases using SQLAlchemy, pd.merge() them into a single dataframe on the primary key column, then create a function that generates a column that flags rows based on the deliverable request.
master_df = pd.merge(
new_db,
old_db,
how="inner",
left_on="external_identifier",
right_on="CUST_ID"
)# 1 = did not import correctly
# 0 = imported correctly
# -1 = did not import correctly
# active = new database
# ACTIVE = old database
def create_to_update_active(row):
if row["active"] == 1 and row["ACTIVE"] == "N":
val = 1
elif row["active"] == 1 and row["ACTIVE"] == "Y":
val = 0
else:
val = -1
return val
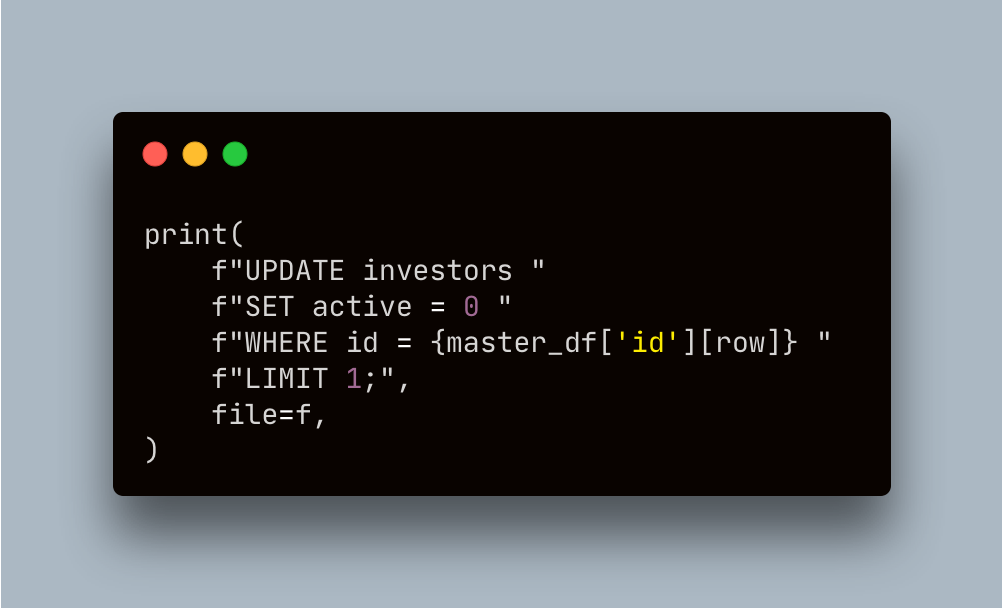
master_df["to_update_active"] = master_df.apply(create_to_update_active, axis=1)We can now apply the function to create the column, allowing us to loop through the dataframe using an if clause, print a SQL statement for each row that is flagged by the 1
f = open(f"{directory}/company_update_active_inactive.sql", "a")
for row in master_df.index:
if master_df["to_update_active"][row] == 1:
print(
f"UPDATE investors SET active = 0, WHERE id = {master_df['id'][row]} LIMIT 1;",
file=f,
)The output is a SQL file
UPDATE investors SET active = 0, WHERE id = 1192756 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1192822 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1192854 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1192877 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1192940 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1193003 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1193004 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1193012 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1193013 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1193026 LIMIT 1;
UPDATE investors SET active = 0, WHERE id = 1193027 LIMIT 1;Now simply open this SQL file in an IDE and run it against the database