This study guide covers AWS Certification for Data Analytics Specialty. This exam replaces the former AWS Big Data Certification, but otherwise covers the same topics. The exam consists of 65 questions, and you have 180 minutes to write it. The study guide below covers everything you need to know for it. To study for this exam I did the following:
- Watched the official AWS Digital Training course
- Read the AWS Data Analytics Specialty Exam Guide accessible here
- Read the AWS Certified Data Analytics Study Guide by Sybex
- Watched the AWS Certified Data Analytics Specialty 2022 - Hands On! Udemy course by Stéphane Maarek
- Watched the AWS Certified Data Analytics - Specialty Whizlabs Course
- Read the following FAQ papers linked below:
- Completed the official AWS practice test that I received after passing the AWS Certified Cloud Practitioner exam
According to Amazon Web Services, this exam will test the following services and features
- Analytics:
- Amazon Athena
- Amazon CloudSearch
- Amazon Opensearch Service (Amazon ES)
- Amazon EMR
- AWS Glue
- Amazon Kinesis (excluding Kinesis Video Streams)
- AWS Lake Formation
- Amazon Managed Streaming for Apache Kafka
- Amazon QuickSight
- Amazon Redshift
- Application Integration:
- Amazon MQ
- Amazon Simple Notification Service (Amazon SNS)
- Amazon Simple Queue Service (Amazon SQS)
- AWS Step Functions
- Compute:
- Amazon EC2
- Elastic Load Balancing
- AWS Lambda
- Customer Engagement:
- Amazon Simple Email Service (Amazon SES)
- Database:
- Amazon DocumentDB (with MongoDB compatibility)
- Amazon DynamoDB
- Amazon ElastiCache
- Amazon Neptune
- Amazon RDS
- Amazon Redshift
- Amazon Timestream
- Management and Governance:
- AWS Auto Scaling
- AWS CloudFormation
- AWS CloudTrail
- Amazon CloudWatch
- AWS Trusted Advisor
- Machine Learning:
- Amazon SageMaker
- Migration and Transfer:
- AWS Database Migration Service (AWS DMS)
- AWS DataSync
- AWS Snowball
- AWS Transfer for SFTP
- Networking and Content Delivery:
- Amazon API Gateway
- AWS Direct Connect
- Amazon VPC (and associated features)
- Security, Identity, and Compliance:
- AWS AppSync
- AWS Artifact
- AWS Certificate Manager (ACM)
- AWS CloudHSM
- Amazon Cognito
- AWS Identity and Access Management (IAM)
- AWS Key Management Service (AWS KMS)
- Amazon Macie
- AWS Secrets Manager
- AWS Single Sign-On
- Storage:
- Amazon Elastic Block Store (Amazon EBS)
- Amazon S3
- Amazon S3 Glacier
Study Guide
Collection
-
Determine the operational characteristics of the collection system
-
Fault Tolerance and Data Persistence
- The Kinesis Producer library can send a group of multiple records in each request to your shards
- If a record fails, it’s put back into the KPL buffer for a retry (Fault Tolerance)
- One record’s failure doesn’t fail a whole set of records
- The KPL also has rate limiting
- Limits per-shard throughput sent from a single producer, can help prevent excessive retries
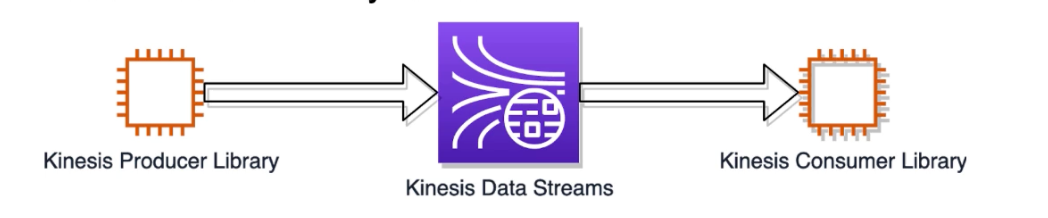
- The Kinesis Producer library can send a group of multiple records in each request to your shards
-
Availability and Durablity of your Ingestion Components
- Kinesis Data Streams replicates your data synchronously across three AZs in one region
- Streams are divided in ordered Shards/Partitions
- One stream is made of many shards
- The number of shards can evolve over time (reshard/merge)
- Records are ordered per shard
- Multiple applications can consume the same stream, ability to reprocess/replay data
- Don’t use Kinesis Data Streams for protracted data persistence
- Your data is retained for 24 hours, which can be extended to 365 days
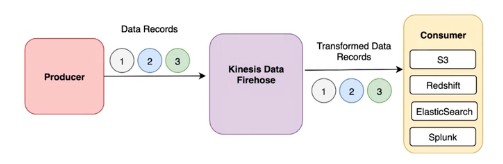
- Kinesis Data Firehose streams your data directly to a data destination, no retention

- Destinations: S3, Redshift, Opensearch, Splunk and Kinesis Data Analytics
- Can transform your data, using a Lambda function, prior to delivering the data
-
Fault Tolerance of your Ingestion Components
- The Kinesis Consumer Library processes your data from your Kinesis Data Stream
- Uses checkpointing using DynamoDB to track which records have been read from a shard
- If a KCL read fails, the KCL uses the checkpoint cursos to resume at the failed record
- Uses checkpointing using DynamoDB to track which records have been read from a shard
- Important facts
- Use unique names for your application in the KCL, since DynamoDB tables use names
- Watch out for provisioning throughput exception in DynamoDB: Too many shards or frequent checkpoint
- Alternatives to the KPL
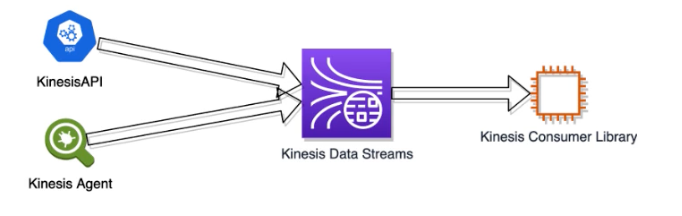
- Use the Kinesis API instead of KPL when you need the fastest processing time
- KPL uses RecordMaxBufferedTime to delay processing to accommodate aggregation
- Kinesis Agent
- Kinesis Agent installs on your EC2 instance
- Monitors files, such as log files, and streams new data to your Kinesis stream
- Emits CloudWatch metrics to help with monitoring and error handling
- Use the Kinesis API instead of KPL when you need the fastest processing time
- The Kinesis Consumer Library processes your data from your Kinesis Data Stream
-
Summary - Determine the operational characteristics of the collection system
- Two key concepts to remember for the exam
- Fault tolerance
- Data persistence
- Kinesis Data Streams vs. Kinesis Data Firehose
- Data persistence is the key difference
- Kinesis Data Streams
- Going to write custom code (producer/consumer)
- Real time(~200 MS latency for classic, ~70 MS latency for enhanced fan-out)
- Must manage scaling (shard splitting/merging)
- Data Storage up to 365 days
- Use with Lambda to insert data into Opensearch
- Kinesis Data Firehose
- Fully managed
- Serverless data transformation with Lambda
- Near real time (lowest buffer time is 1 minute)
- Automated Scaling
- No Data storage
- Kinesis Producer Library vs. Kinesis API vs. Kinesis Agent
- Fault tolerance and appropriate tools for your data collection problem
- Kinesis Data Streams vs SQS
- Kinesis Data Streams
- Data can be consumed many times
- Data is deleted after the retention period
- Ordering of records is preserved (at the shard level) - even during replays
- Build multiple applications reading from the same stream independently
- Checkpointing to track progress of consumption
- Shards(capacity) must be provided ahead of time
- SQS
- Queue, decouple applications
- One application per queue
- Records are deleted after consumptions
- Messages are processed interdependently for standard queue
- Ordering for FIFO queues
- Capability to ‘delay’ messages
- Dynamic scaling of load
- Kinesis Data Streams
- Kinesis Data Streams vs MSK
- Kinesis Data Streams
- 1 MB message size limit
- Data Streams with Shards
- Shard Splitting and Merging
- TLS in-flight encryption
- KMS at-rest encryption
- Security
- IAM policies for AuthN/AuthZ
- MSK
- 1 MB default, configure for higher
- Kafka Topics with Partitions
- Can only add partitions to a topic
- plaintext or TLS in-flight encryption
- KMS at-rest encryption
- Security
- MutualTLS(AuthN) + Kafka ACLs(AuthZ)
- SASL/SCRAM(AuthN) + Kafka ACLs(AuthZ)
- IAM Access Control (AuthN + AuthZ)
- Kinesis Data Streams
- Two key concepts to remember for the exam
-
Data Collection through Real-Time Streaming Data
- Kinesis Data Firehose is fully managed
- Destinations: S3, Redshift, Opensearch, Splunk, Kinesis Data Analytics
- Can optionally transform data, using Lambda, before delivering it to its destination
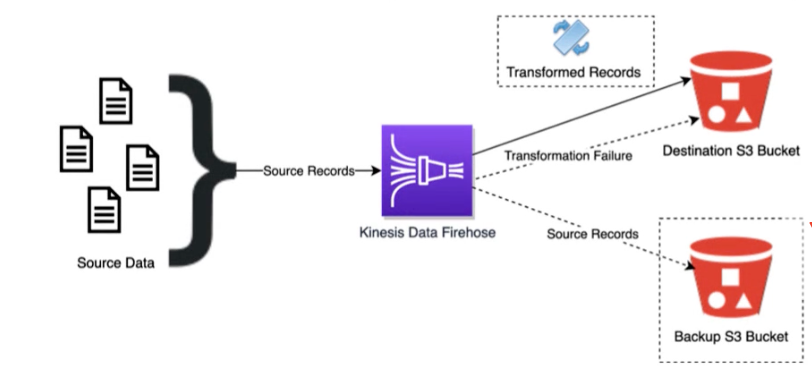
- Firehose to Redshift
- Delivers directly to S3 first
- Firehose then runs a Redshift COPY command
- Can optionally transform your data, using Lambda, before delivering it to its destination
- Firehose to Opensearch Cluster
- Firehose delivers directly to Opensearch cluster
- Can optionally backup to S3 concurrently
- Firehose to Splunk
- Firehose delivers directly to Splunk instance
- Can optionally backup to S3 concurrently
- Firehose Producers
- Firehose producers send records to Firehose
- Web server logs data
- Kinesis Data Stream
- Kinesis Agent
- Kinesis Firehose API using the AWS SDK
- CloudWatch logs and/or events
- AWS IoT
- Firehose buffers incoming streaming data for a set buffer size (MBs) and a buffer interval (seconds). You can manipulate the buffer size in the buffer interval to speed up or slow down your firehose delivery speed
- use case: you’re delivering streaming data from Firehose to an S3 bucket, how might you speed up the delivery of your Kinesis Data? Lower the buffer size and lower the buffer interval
- Firehose producers send records to Firehose
-
-
Select a collection system that handles the frequency, volume, and the source of data
-
The Four Ingestion Services
- Kinesis Data Streams
- Use cases needing custom processing and different stream processing frameworks where sub-second processing latency is needed
- Kinesis Data Firehose
- Use cases needing managed service streaming to S3, Redshift, Opensearch, or Splunk where data latency of 60 seconds or higher is acceptable
- AWS Database Migration Service
- Use cases needing one-time migration and/or continuous replication of database records and structures to AWS services
- AWS Glue
- Use cases needing ETL batch-oriented jobs where scheduling of ETL jobs is required
- Kinesis Data Streams
-
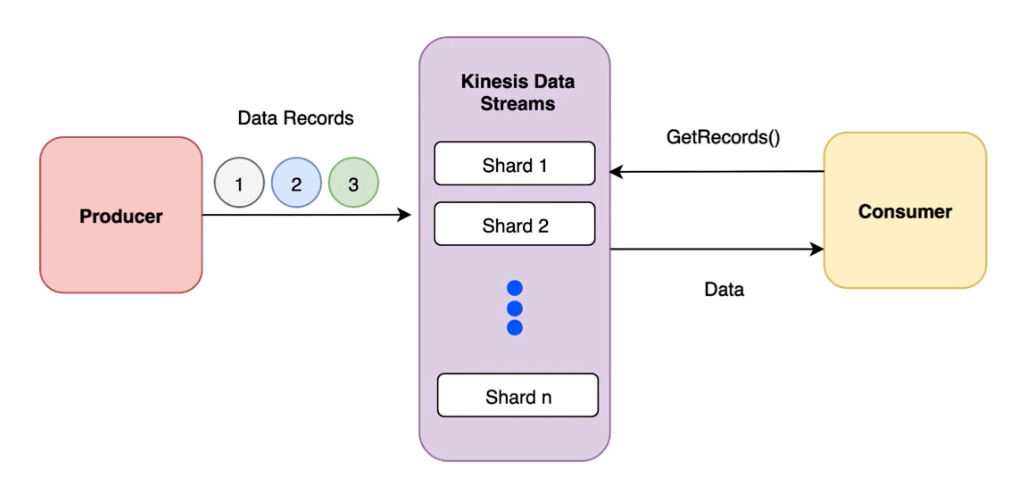
Kinesis Data Streams
- Each shard supports
- 1,000 RPS for writes with max of 1 MB/sec
- 5 TPS for reads at a max of 2MB/sec using GetRecords API Call
- Stream total capacity equals the sum of the capacity of the shards
- No limit to the number of shards you can provision
- Data Blob
- data being sent, serialized as bytes
- Record Key
- Sent alongside a record, helps to group records in shards. Same key = same shard
- Use highly distributed key to avoid the “hot partition”
- Sequence number
- Unique identifier for each record put in shards. Added by Kinesis after ingestion
- Producer
- Kinesis Producer SDK - PutRecords(s)
- APIs that are used are
PutRecordandPutRecords PutRecordsuses batching and increases throughput => less HTTP requestsProvisionedThroughputExceededif we go over the limit- Happens when sending more data(exceeding MB/sec or TPS for any shard)
- Make sure you don’t have a hot shard(such as your partition key is bad and too much data goes into that partition)
- Solution
- Retries with backoff (2,4,8 seconds)
- Increase shards(scaling)
- Ensure your partition key is a good one
- Use case: low throughput, high latency, simple API, AWS Lambda
- Anti-Pattern: applications that cannot tolerate
RecordMaxBufferedTimedelay, therefore use the SDK directly - We can influence the batching efficiency by introducing some delay with
RecordMaxBufferedTime(default 100ms) - Managed AWS sources for KDS that use the SDK behind the scenes
- CloudWatch Logs
- AWS IoT
- Kinesis Data Analytics
- APIs that are used are
- Kinesis Producer Library (KPL)
- Easy to use and highly configurable C++/Java library
- Used for building high performance, long-running producers
- automated and configurable
retrymechanism - Synchronous or Asynchronous API (better performance for async)
- Batching: increases throughput and decreases cost
- Collect
- Records and writes to multiple shards in the same PutRecords API call
- Aggregate
- Increased latency
- Capability to store multiple records in one record (go over 1000 records/sec limit)
- Increase payload size and improve throughput (maximize 1MB/sec limit)
- Collect
- Compression must be implemented by user
- When Not to Use the KPL: The KPL can incur an additional processing delay of up to
RecordMaxBufferedTimewithin the library (user-configurable). Larger values ofRecordMaxBufferedTimeresults in higher packing efficiencies and better performance. Applications that cannot tolerate this additional delay may need to use the AWS SDK directly. For more information about using the AWS SDK with Kinesis Data Streams, see Developing Producers Using the Amazon Kinesis Data Streams API with the AWS SDK for Java
- Kinesis Agent
- Monitor Log files and sends them to KDS
- Install only in Linux based environments
- Features
- Write to multiple directories and write to multiple streams
- Routing feature based on directory/log file
- Pre-process data before sending to streams
- Handles file rotation, checking, and retry upon failures
- Emits metrics to CloudWatch for monitoring
- Kinesis Producer SDK - PutRecords(s)
- Consumer
- Kinesis Consumer SDK - GetRecords
- Classic Kinesis: Records are polled by consumers from a shard
- Each shard has 2MB total aggregate throughput
GetRecordsreturns up to 10MB of data (then throttle for 5 seconds) or up to 1000 records- Maximum of 5
GetRecordsAPI calls per shard per second = 200ms latency - If 5 consumer applications consume from the same shard, means every consumer can poll once a second and receive less than 400 KB/sec
- Kinesis Client Library (KCL)
- Read records from Kinesis produced with the KPL (de-aggregation)
- Share multiple shards with multiple consumers in one ‘Group’, shard discovery
- Checkingpoint feature to resume progress
- Leverages DynamoDB for coordination and checkpointing (one row per shard)
- Make sure you provision enough WCU/RCU
- Or use On-Demand for DynamoDB
- Otherwise DynamoDB may slow down KCL
- Record processors will process the data
ExpiredIteratorException> increase WCU
- Kinesis Connector Library
- Older java library (2016), leverages the KCL library
- Must be running on an EC2 instance
- Deprecated: Kinesis Firehose/Lambda replaces this
- Lambda
- Lambda can source records from Kinesis Data Streams
- Has a library to de-aggregate records from the KPL
- Lambda can be used to run lightweight ETL
- Can be used to trigger notifications/send emails in real time
- Configurable batch size
- Kinesis Consumer SDK - GetRecords
- Kinesis Enhanced Fan Out
- Each consumer get 2 MB/sec of provisioned throughput per shard
- That means that if we have 20 consumers, overall we’ll get 40 megabytes per second, per shard.
- Before we had a 2 MB/sec limit per shard, but now, we get 2 MB/sec per limit per shard per consumer
- Pushes data to consumers over HTTP/2
- Reduced latency (~70 MS)
- Costs a bit more
- Enhanced Fan-Out vs. Standard Consumers Use Cases
- Standard
- Low number of consuming applications (1,2,3…)
- Can tolerate ~200 MS latency
- Minimize Cost
- Enhanced Fan Out Consumers
- Multiple Consumer applications for the same Stream
- Low Latency requirements ~70 MS
- Higher costs
- Default limit of 5 consumers using enhanced fan-out per data stream
- Standard
- Scaling
- Adding Shards
- Also called ‘Shard Splitting’
- Can be used to increase the Stream capacity (1 MB/sec per shard)
- Can be used to divide a ‘hot shard’
- The old shard is closed and will be deleted once the data is expired
- Merging Shards
- Decrease the Stream capacity and save costs
- Can be used to group two shards with low traffic
- Old shards are closed and deleted based on data expiration
- Out of order records after resharding
- After a reshard, you can read from child shards
- However, data you haven’t read yet could still be in the parent
- If you start reading the child before completing reading the parent, you could read data for a particular hash key out of order
- After a reshard, read entirely from the parent until you don’t have new records
- The Kinesis Client Library has this logic already built-in, even after resharding operations
- Auto Scaling
- Auto Scaling is not a native feature of Kinesis
- Can be implemented with Lambda
- Handling Duplicate Records
- Producer side
- Producer retries can create duplicates due to network timeouts
- Although the two records have identical data, they also have unique sequence numbers
- Fix: Embed unique record ID in the data to de-duplicate on the consumer side
- Consumer side
- Consumer retries can make your application read the same data twice
- Consumer retries happen when record processors restart:
- A worker terminates unexpectedly
- Worker instances are added or removed
- Shards are merged or split
- The Application is deployed
- Fix: Make your consumer application idemptotent
- If the final destination can handle duplicate, it’s recommended to do it there
- Producer side
- Adding Shards
- Limits
- Producer
- 1 MB/sec or 1000 messages/sec at write PER SHARD
ProvisionedThroughputExceptionotherwise
- Consumer Classic
- 2 MB/sec at read PER SHARD across all consumers
- 5 API calls per second PER SHARD across all consumers
- Consumer Enhanced Fan-Out
- 2 MB/sec at read PER SHARD, PER ENHANCED CONSUMER
- No API calls needed (push model)
- Scaling
- Resharding cannot be done in parallel; so that means you can’t reshard a thousand streams at a time or a thousand shards at a time
- Takes a few seconds: For 1000 shards, it takes 30,000 seconds to double the shards to 2000
- Producer
- Each shard supports
-
Kinesis Data Firehose
- Firehose automatically delivers to specified destination, near real time service (60 second latency for non-full batches)
- Can deliver to any HTTP Endpoint
- Fully managed service, has automatic scaling
- Support data conversion from JSON to Parquet/ORC
- Data transformation through AWS Lambda
- Supports compression when target is S3 (GZIP, ZIP, and SNAPPY)
- Only GZIP is supported by Redshift
- Pay for the amount of data going through Firehose
- Spark/KCL do not read from Data Firehose
- You can deposit the source data directly into S3
- Buffers incoming streaming data to specified size or for a specified period of time before delivering to destinations
- Firehose accumulates reocrds in a buffer
- The buffer is flushed based on time and size rules
- Buffer Size (Ex. 32 MB): If that buffer size is reached, it’s flushed
- Buffer Time (Ex. 2 Minutes): If that time is reached, it’s flushed
- Firehose can automatically increase the buffer size to increase throughput
- High Throughput > Buffer size will be hit
- Low Throughput > Buffer time will be hit
- Automatically scales to match data throughput
- No manual intervention or developer overhead required
-
Data Migration Service
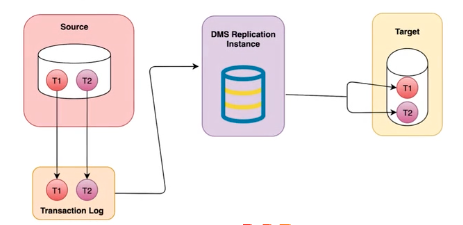
- DMS is used to take data from a source database to a destination target (database, data lake, data warehouse)
- Source database remains fully operational during the migration
- Supports several data engines as a source and target for data replication
- Uses tasks to capture ongoing changes after initial migration to a supported target data store
- Ongoing replication or Change Data Capture
- Uses database engine’s APIs to read changes from transaction log then replicate to target database
- EC2 replication instance, scale to meet utilization requirements
- Schema Conversion Tool allows you to convert your database’s schema from one engine to another
-
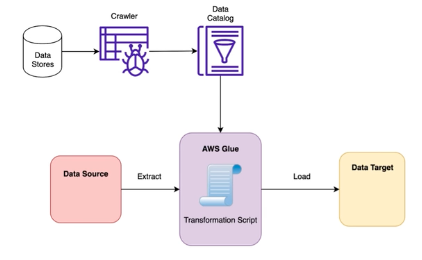
AWS Glue
- Key Point: Batch oriented (although now it supports Streaming)
- Micro-batches but no streaming data
- Does not support NoSQL databases as data source
- Crawl data source to populate data catalog
- Generate a script to transform data or write your own in console or API
- Run jobs on demand or via a trigger event
- Glue catalog tables contain metadata not data from the data source
- Uses a scale-out Apache Spark environment when loading data to destination
- Allocate data processing units (DPUs) to ETL jobs
- Glue crawler scans data in S3, creates schema and populates the Glue Data Catalogue
- Glue crawler will extract partitions based on how your S3 data in organized
- Glue can integrate with most SQL databases, regardless of whether they are AWS services.
- Running Glue Jobs
- Job bookmarks
- Persists state from the job run
- Prevents reprocessing of old data
- Allows you to process new data only when re-running on a schedule
- CloudWatch Events
- Fire off a Lambda function or SNS notification when ETL succeeds or fails
- Invoke EC2 run, send event to Kinesis, activate a Step Function
- Job bookmarks
- Streaming
- Glue ETL supports serverless streaming ETL
- Consumes from Kinesis of Kafka
- Clean and transform in-flight
- Store results into S3 or other data stores
- Runs on Spark Structured Streaming
- Glue ETL supports serverless streaming ETL
- Glue DataBrew
- Visual data preparation tool
- UI for pre-processing large data sets
- Input from S3, data warehouse, or database
- Output to S3
- You can create ‘recipes’ of transformations that can be saved as jobs
- Key Point: Batch oriented (although now it supports Streaming)
-
AWS SQS
- Summary
- SQS will send a message to the SQS Queue and a consumer, or consumers, will pull messages from that Queue.
- fully managed and it will scale automatically.
- Even if you have 1 message per second to 10,000 messages per second there are no limit to how many messages per seconds you can send to SQS
- The default retention period of a message is 4 days but, you can have a maximum of 14 days
- There’s no limit to how many messages can be in the queue
- There has extremely low latency
- There is horizontal scaling in terms of the number of consumers who can scale as many consumers as you want
- Limit of 256 KB per message
- Producing Messages
- Define Body
- Add message attributes
- Provide Delay Delivery
- Consuming Messages
- Poll SQS for messages (up to 10 at a time)
- Delete the message using the message ID and receipt handle
- Cannot be handled by different consumers like Kinesis
- FIFO Queue
- Lower throughput (up to 3,000 messages per second with batching, 300 messages per second without)
- Messages are processed in order by the consumer
- Messages are sent exactly once
- Trade off: less throughput but exact ordering
- Use Cases
- Decouple Applications
- Buffer writes to a database
- Handle large loads of messages coming in
- SQS can be integrated with Auto Scaling through CloudWatch
- Limits
- Maximum 120,000 in flight messages processed by consumers
- Batch Request has a maximum of 10 messages - Max 256KB
- Summary
-
AWS MSK
- Alternative to Kinesis
- Fully managed Apache Kafka on AWS
- Allows you to create, update, delete clusters
- MSK creates and manages Kafka broker nodes, Zookeeper nodes for your
- Deploy the MSK cluster in your VPC, multi-AZ (up to 3 for HA)
- Automatic recovery from common Apache Kafka failures
- Data is stored on EBS volumes
- You can build producers and consumers of data
- Can create custom configurations for your clusters
- Default message size of 1 MB
- Possibilities of sending large messages into Kafka after customer configuration
- Security
- Encryption
- Optional in-flight using TLS between the brokers
- Optional in-flight with TLS between the clients and brokers
- At rest encryption for your EBS volumes using KMS
- Encryption
- Monitoring
- CloudWatch Metrics
- Basic monitoring
- CloudWatch Metrics
-
The Three Types of Data to Ingest
- Batch Data
- Applications logs, video files, audio files, etc.
- Larger event payloads ingested in an hourly, daily, or weekly daily
- Ingested in intervals from aggregated data
- Streaming Data
- Click-stream data, IoT sensor data, stock ticker data, etc.
- Ingesting large amounts of small records continuously and in real-time
- Transactional Data
- Initially load and receive continuous updates from data stores used as operational business databases
- Similar to batch data but with a continuous update flow
- Ingested from databases storing transactional data
- Batch Data
-
Batch Data
- Data is usually ‘colder’ and can be processed on less frequent intervals
- Use AWS batch-oriented services like Glue
- EMR support batch processing on a large scale
- Latency is minutes to hours
- Complex analytics across big data sets
- Data is usually ‘colder’ and can be processed on less frequent intervals
-
Streaming Data
- Often bound by time or event sets in order to produce real-time outcomes
- Data is usually ‘hot’ arriving at a high frequency that you need to analyze in real-time
- Use Kinesis Data Streams, Kinesis Data Firehose, Kinesis Data Analytics
- Can load data into data lake or data warehouse
- Individual records or aggregated micro-batches
- low-latency, i.e. milliseconds
- Simpler analytics, rolling metrics, aggregations
-
Transactional Data
- Data stored at low latency and quickly accessible
- Load data from a database on-prem or in AWS
- Use Database Migration Service
- Can load data from relational databases, data warehouses and NoSQL databases
- Can convert to different database systems using the AWS Schema Conversion Tool (AWS SCT) then use DMS to migrate your data
-
Comparing the Data Collection Systems
- Understand how each ingestion approach is best used
- Throughput, bandwidth, scalability
- Availability and fault tolerance
- Cost of running the services
- Understand Differences between Services
Kinesis Data Streams Kinesis Data Firehose Data Migration Service Glue Use when you need custom producers and consumers Use cases where you want to deliver directly to S3, Redshift, Opensearch, or Splunk Use cases when you need to migrate data from one database to another Batch-oriented use cases where you want to perform an Extract Transform Load(ETL) process Use cases that require sub-second processing Use cases where you can tolerate latency of 60 seconds or greater Use cases where you want to migrate a database to a different database engine Not for use with streaming use cases Use cases that require unlimited bandwidth Use cases where you wish to transform your data or convert the data format - Throughput, Bandwidth, Scalability
Kinesis Data Streams Kinesis Data Firehose Data Migration Service Glue Shards can handle up to 1,000 PUT records per second Automatically scales to accommodate the throughput of your stream EC2 instances used for the replication instance Runs in a scale-out Apache Spark environment to move data to target system Can increase the number of shards in a stream without limit You need to scale your replication instance to accommodate your throughput Scales via Data Processing Units (DPU) for your ETL jobs Each shard has a capacity of 1 MB/s for input and 2 MB/s output - Availability and Fault Tolerance
Kinesis Data Streams Kinesis Data Firehose Data Migration Service Glue Synchronously replicates your shard data across 3 Availability Zones Synchronously replicates your shard data across 3 Availability Zones Can use multi-AZ for replication that gives you fault tolerance via redundant replication servers Retries 3 times before marking an error condition For S3: Firehose retries for 24 hours,if failure persists past 24 hours your data is lost Create a CloudWatch alert for failures that triggers an SNS message For Redshift, you can specify a retry duration from 0 to 7,200 seconds For Elastic Search, you can specify a retry duration from 0 to 7,200 seconds For Splunk, you can use a retry duration counter. Firehose retires until counter expires, then backs up your data to S3 Retries may cause duplicate records - Understand how each service incurs cost
Kinesis Data Streams Kinesis Data Firehose Data Migration Service Glue Pay per shard hour and PUT payload unit Pay for the volume of data ingested Pay for the EC2 compute resources you use when migrating Pay an hourly rate at a billing per second for both crawlers and ETL jobs Extended data retention and enhanced fanout incur additional cost Pay for data conversions Pay for log storage Monthly fee for storing and accessing data in your Glue data catalogue Data transfer fees - Understand how each ingestion approach is best used
-
Select a collection system that addresses the key properties of data, such as order, format, and compression
- Managing Data Order, Format and Compression
- Problems with your streaming data
- Data that is out of order
- Data that is duplicated
- Data where we need to change the format
- Data that needs to be compressed
- Methods to address these problems
- Choose an ingestion service that has guaranteed ordering
- Kinesis Data Streams
- DynamoDB Streams
- Choose an ingestion service that has deduping capacity
- DynamoDB Streams - exactly-once
- Kinesis Data Streams - at-least-once
- Embed a primary key in data records and remove duplicates later when processing
- Kinesis Data Firehose - at-least-once
- Crawl target data with Glue ML FindMatches Transform
- Use conversion or compression feature of ingestion service
- Kinesis Data Streams
- Use Lambda consumer to format or compress
- Use KCL application to format or compress
- Kinesis Data Firehose
- Use format conversion feature if data in JSON
- Use Lambda transform to preprocess format conversion feature if data not JSON
- Use S3 compression (GZIP, Snappy, or Zip)
- Use GZIP COPY command option for Redshift compression
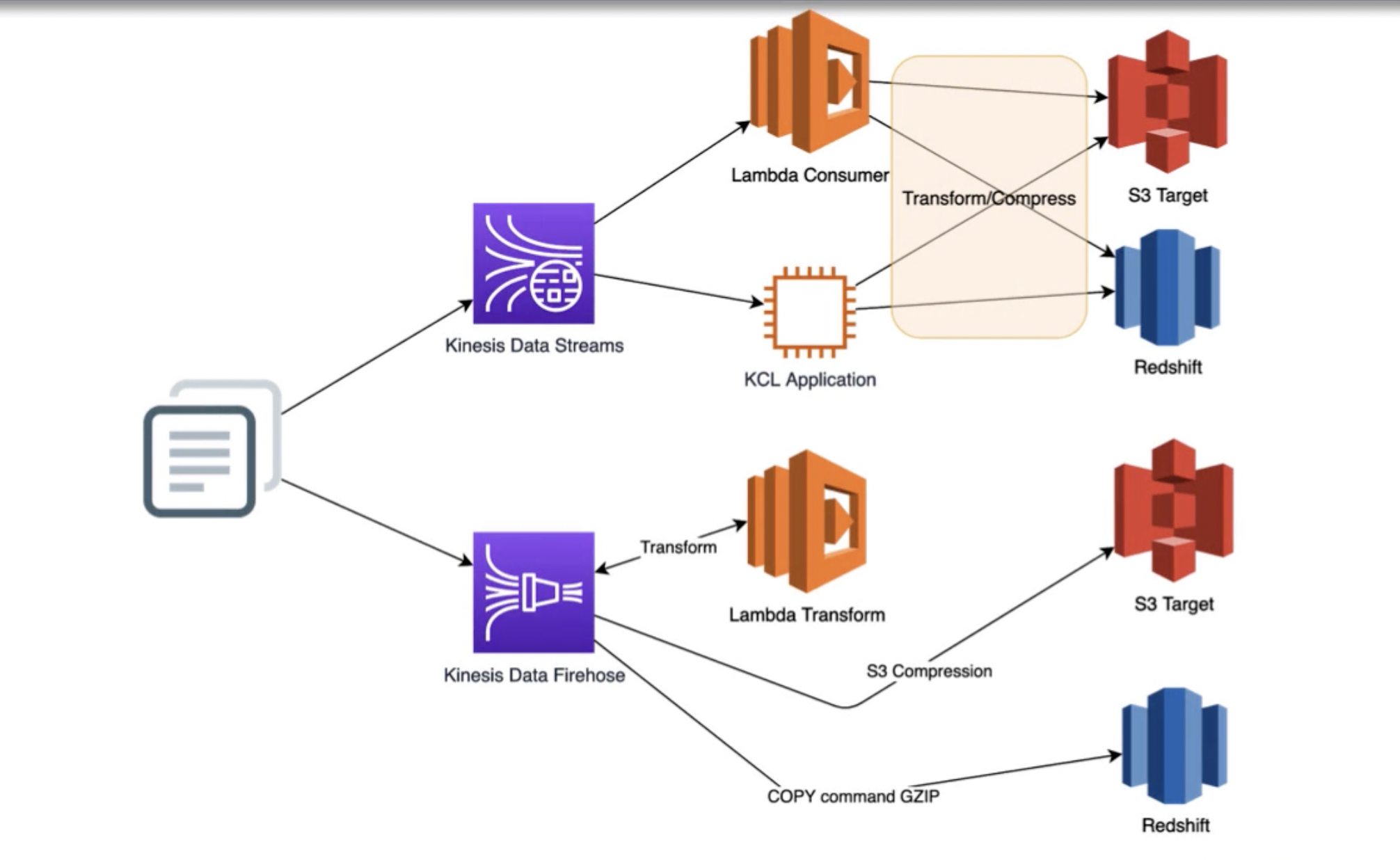
- Kinesis Data Streams
- Choose an ingestion service that has guaranteed ordering
- Problems with your streaming data
- Transforming Data when Ingesting
- Kinesis Data Firehose
- Using Lambda, Firehose sends buffered batches to Lambda for transformation
- Batch, encrypt, and/or compress data
- Lambda
- Convert the format of your data, e.i. GZIP -> JSON
- Transform your data, e.g. expand strings into individual columns
- Filter your data to remove extraneous info
- Enrich your data, e.g. error correction
- Database Migration Service
- Table and schema transformations, e.g. change table, schema and/or column names
- Kinesis Data Firehose
- Managing Data Order, Format and Compression
-
Storage and Data Management
-
Determine the operational characteristics of the storage solution for analytics
-
Selecting your storage components
- Take into account the cost, performance, latency, durability, consistency, and shelf-life or your data
- Choose the correct storage system
- Operational

- Data stored as rows
- Low latency
- High throughput
- Highly concurrent
- Frequent changes
- Benefits from caching
- Often used in enterprise critical applications
- Analytic

- Two types:
- OLAP: ad-hoc queries
- DSS: long running aggregations
- Data stored as columns
- Large datasets that take advantage of partitioning
- Frequent complex aggregations
- Loaded in bulk or via streaming
- Less frequent changes
- Two types:
- Operational
- Choose the correct storage system
- Take into account the cost, performance, latency, durability, consistency, and shelf-life or your data
-
RDS - distributed relational database service
- Use cases
- E-Commerce, web, mobile
- Fast OLTP database options
- SSD-backed storage options
- Scale
- Vertical scaling
- Instance and storage size determine scale
- Reliability and durability
- Multi-AZ
- Automated backups and snapshots
- Automated failover
- Use cases
-
DynamoDB- fully managed NoSQL database
- Use cases
- Ad Tech, Gaming, Retail, Banking, and Finance
- Fast NoSQL database options
- Single-digit millisecond latency at scale
- Scale
- Horizontal scaling
- Can store data without bounds
- High performance and low cost even at extreme scale
- Reliability and durability
- Data replicated across three AZs
- Global-tables for multi region replication
- Basics
- Maximum size of an item is 400 KB
- Primary Keys
- Option 1
- Partition Key only (HASH)
- Key must be unique for each item
- Example: user_id
- Option 2
- The combination must be unique
- Data is grouped by partition key
- Sort key == range key
- Example: user_id for the partition key, game_id for the sort key
- Option 1
- Anti-patterns
- Joins or complex transactions
- BLOB data
- Large data with low I/O rate
- Provisioned Throughput
- Table must have provisioned read and write capacity units
- Option to set up auto-scaling of throughput to meet demand
- Throughput can be exceeded temporarily using ‘burst credit’
- If burst credit is empty, you’ll get a
ProvisionedThroughputException - If we exceed our RCU or WCU, we get
ProvisionedThroughputExceededException- Reason: hot key, large items
- By default, DynamoDB uses Eventually Consistent Reads
- Write Capacity Units
- One WCU represents one write per second for an item up to 1 KB in size
- Example
- 10 objects per seconds of 2 KB each: 2 * 10 = 20 WCU
- 6 objects per second of 4.5 KB each: 6 * 5 = 30 WCU
- 120 objects per minute of 2 KB each: 120/60 * 2 = 4 WCU
- Read Capacity Units
- One read capacity unit represents one strongly consistent reads per second, or two eventually consistent reads per second, for an item up to 4 KB in size’
- If the items are larger than 4 KB, more RCU are consumed
- Example
- 10 strongly consistent reads per seconds of 4 KB each: 10 * 4 / 4 = 10 RCU
- 16 eventually consistent reads per second of 12 KB each: (16/2) * (12/4) = 24 RCU
- 10 strongly consistent reads per second of 6 KB each: 10 * 8 / 4 = 20 RCU (we have to round up 6 KB to 8 KB)
- Partitions
- You start with one partition
- Each partition has a max of 3000 RCU/1000 WCU, and 10GB
- To compute the number of partitions
- By Capacity: (total RCU / 3000) + (total WCU / 1000)
- By Size: total size / 10 GB
- Total Partitions: CEILING(MAX(Capacity, Size))
- Writing Data
PutItem- write data to DynamoDBUpdateItem- Update data in DynamoDBBatchWriteItem- up to 25PutItemand/orDelete Itemin one call- Conditional Writes
- Accept a write/update only if conditions are
- Reading Data
GetItem- read based on primary keyBatchGetItem- Up to 100 items, up to 16 MB of data
- Scan
- Scan the entire table and then filter out data (inefficient)
- Indexes
- LSI (Local Secondary Index)
- The LSI is an alternate range key or sort key for your table that is local to the hash key, so the partition key stays the same, but you have an alternate range key
- Up to five local secondary indexes per table
- The sort key consists of exactly one scalar attribute
- The attribute that you choose must be a scalar String, Number or Binary
- LSI must be defined at table creation
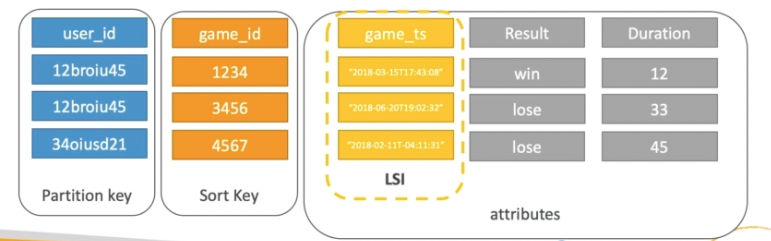
- GSI (Global Secondary Index)
- To speed up queries on non-key attributes, use a Global Secondary Index
- GSI = partition key + optional sort key
- The index is a new ‘table’ and we can project attributes on it
- LSI (Local Secondary Index)
- DAX
- Seamless cache for DynamoDB, no application re-write
- Writes go through DAX to DynamoDB
- Micro second latency for cached reads and queries
- Solves the Hot Key problem (too many reads)
- 5 TTL for cache by default
- Up to 10 nodes for the cluster
- DynamoDB Streams
- Changes in DynamoDB(Create, Update, Delete) can end up in a DynamoDB Stream
- This stream can be read by AWS Lambda, and we can then do:
- React to changes in real time
- Create tables/views
- Insert into OpenSearch
- Stream has 24 hours of data retention
- Configure batch size up to 1000 rows or 6 MB of data
- TTL
- Automaticlaly delete an item after an expiry date/time
- Helps reduce storage and manage the table size, as well as helps adhere to regulatory norms
- Storing Large Objects
- Max size of an item is 400 KB
- For large objects, store them in S3 and reference them in DynamoDB
- Use cases
-
Elasticache - fully managed Redis and Memecache
- Use cases
- Caching, session stores, gaming, real-time analytics
- Sub-millisecond response time from in-memory data store
- Single digit millisecond latency at scale
- Reliability and durability
- Redis Elasticache offers Multi-AZ with automatic failover
- Timestream - fully managed time series database
- Use cases
- IoT applications, industrial telemetry, application monitoring
- Fast: analyze trillions of events per day
- One tenth the cost of relational database
- Scale
- Vertical scaling
- Timestream scales up or down depending on your load
- Reliability and durability
- Managed service takes care of provisioning, patching, etc.
- Retention policies to manage reliability and durability
- Use cases
-
Redshift - Cloud Data Warehouse
- Use cases
- Data science queries, marketing analysis
- Fast: columnar storage technology that parallelize queries
- Millisecond latency queries
- Reliability and durability
- Data replicated within the Redshift cluster
- Continuous backup to S3
- Use cases
-
S3
- Use cases:
- Data lake, analytics, data archiving, static websites
- Fast: query structured and structured data
- Use Athena and Redshift Spectrum to query at low latency
- Reliability and Durability
- Data replicated across three AZs in a region
- Same-region or cross-region replication
- Storage
- Max size is 5TB
- Strongly consistent
- After a successful write of a new object, or an overwrite or delete of an existing object, any subsequent read request immediately receives the latest version of the object
- Event Notifications
- Events can happen in your S3 bucket, for example, a new object is created, removed, restored, or replicated
- You want to be able to react to all these events. You can create rules which you can use to filter by object names
- Use cases:
-
Data Freshness
- Considering your data freshness when selecting your storage system components
- Place hot data in cache (Elasticache or DAX) or NoSQL (DynamoDB)
- Place warm data in SQL data stores (RDS)
- Can use S3 for all types (hot, warm, cold)
- Use S3 Glacier for cold data
- Considering your data freshness when selecting your storage system components
-
Operational Characteristics of DynamoDB
- DynamoDB Tables
- Attributes - Columns
- Items - Rows
- Must have a primary key, two types
- Partition Key: primary key with one attribute called the hash attribute
- DynamoDB hash function determines the partition where an item is located
- Composite Key: partition key plus sort key where all items with the same sort key are located together ordered by sort key value
- Partition Key: primary key with one attribute called the hash attribute
- No limit to number of items in a table
- Maximum item size is 400KB
- DynamoDB Consistency
- DynamoDB has eventual and strong consistency
- Eventually consistent reads (default)
- Achieves maximum read throughput
- May return stale data
- Strongly consistent reads
- Returns result representing all prior write operations
- Always accurate data returned (no stale data)
- Increased latency with this option
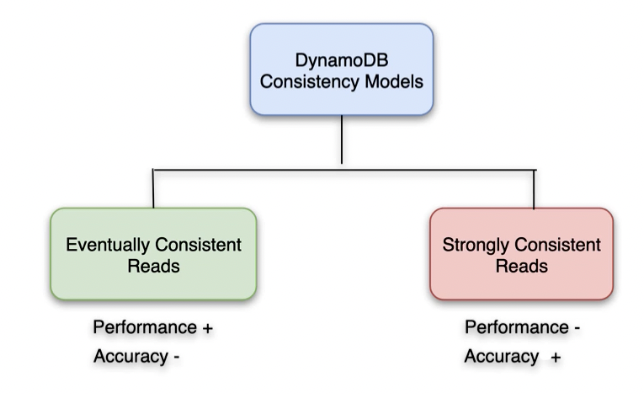
- Eventually consistent reads (default)
- DynamoDB has eventual and strong consistency
- DynamoDB Capacity
- Cost versus performance - two capacity modes
- On-demand capacity
- DynamoDB automatically provisions capacity based on your workload, up or down
- Provisioned capacity
- Specify read capacity units (RCUs) and write capacity units (WCUs) per second for your application
- One RCU equals one strongly consistent read or two eventually consistent reads per second for items up to 4KB
- One WCU equals one write per second for items up to 1KB
- Can use auto scaling to automatically calibrate your table’s capacity
- On-demand capacity
- Cost versus performance - two capacity modes
- DynamoDB Global Tables
- Specify multiple regions in which your table(replica) is available
- DynamoDB propagates all changes across all regions
- Any change to an item in any replica is propagated to all other replicas
- New items propagated within seconds
- User last-writer-wins reconciliation
- When a table in a region has issues, application directs to a different region
- DynamoDB Tables
-
Redshift
- Redshift Overview
- Enterprise-class data warehouse and relational database query and management system
- Connect using many types of client applications
- Business Intelligence
- Reporting
- Analytics
- Build multi-stage query operations that retrieve, compare and evaluate large amounts of data
- Efficient storage and optimum query performance
- Massively parallel processing
- Columnar data storage
- Very efficient, targeted data compression encoding schemes
- Redshift Architecture
- Based on PostgreSQL
- Clients connect via JDBC and ODBC
- Built upon clusters
- One or more compute nodes
- If greater than 1 compute nodes, a leader node coordinates the compute nodes and communicates with external client apps
- Leader node
- Builds execution plans to execute database operations - complex queries
- Complies code and distributes it to the compute nodes, also assigns a portion of data to each compute node
- Compute nodes
- Executes the compiled code and sends intermediate results back to the leader node for final aggregation
- Has dedicated CPU, memory and attached disk storage, which are determined by the node type
- Node types
- RA3
- DC2
- DS2
- Node types
- User data stored on compute nodes
- Node Slices
- Compute nodes are partitioned into slices
- Slices are allocated a portion of the node’s memory and disk space
- Processes a part of the workload assigned to the node
- Leader node distributes data to the slices, divides query workload to the slices
- Slices work in parallel to complete your queries
- Assign a column as a distribution key when you create your table on Redshift
- When you load data into your table, rows are distributed to the node slices by the table distribution key - facilitates parallel processing
- Columnar Storage
- Drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from disk
- In relational databases, data blocks store values sequentially for each consecutive column making up the entire row
- In a columnar databases, each data block stores values of a single column for multiple rows
- Drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from disk
- Moving data in Redshift
- Redshift integrates well with AWS services to move, transform, and load your data quickly and reliably
- S3
- Leverages parallel processing to export data from Redshift to S3
- DynamoDB
- Use COPY command to move tables
- SSH / Remote Host
- Execute COPY command to load data from remote hosts such as EC2 and EMR
- Data Pipeline
- You can automate data movement and transformation into and out of Redshift using the scheduling capabilities
- DMS
- Move data back and forth between Redshift and other relational databases
- S3
- Redshift integrates well with AWS services to move, transform, and load your data quickly and reliably
- Redshift Overview
-
Snow family
- Snowcone
- Small portable computing, anywhere, rugged and secure
- Device used for edge computing, storage, and data transfer
- 8 TB of usable storage
- Can be used offline
- Snowball Edge
- Move TB or PB of data in or out of AWS
- Snowball Edge Storage Optimized
- 80 TB of HDD Capacity
- Snowball Edge Compute Optimized
- 42 TB of HDD Capacity
- Use Cases: Data cloud migrations, DC Decommission, Disaster Recovery
- Snowmobile
- Transfer of exabytes of data
- High Security
- Better than snowball if you transfer more than 10 PB of data
- Snowcone
-
-
Determine data access and retrieval patterns
-
Data Access and Retrieval Patterns
- Characteristics of your data
- What type of data are you storing?
- Data storage life cycle
- How long do you need to retain your data?
- Data access retrieval and latency requirements
- How fast does your retrieval need to be?
- Characteristics of your data
-
Characteristics of your data
- Structured data is consists of clearly defined data types with patterns that make them easily searchable and is stored in a predefined format, where unstructured data is a conglomeration of many varied types of data that are stored in their native formats. This means that structured data takes advantage of schema-on-write and unstructured data employs schema-on-read.
- Structured data
- Examples: accounting data, demographic info, logs, mobile device geolocation data
- Storage options: RDS, Redshift
- Unstructured data
- Examples: email text, photos, video audio, pdfs
- Storage options: S3 Data Lake, DynamoDB
- Semi Structured data
- Examples: email metadata, digital photo metadata, video metadata, JSON data
- Storage options: S3 Data Lake, DynamoDB
-
Data Lake or Data Warehouse
- Data Warehouse
- Optimized for relational data produced by transactional systems
- Data structure, schema predefined which optimizes fast SQL queries
- Used for operational reporting and analysis
- Data is transformed before loading
- Data Lake
- Relational data and non-relational data: mobile apps, IoT devices, and social media
- Data structure/schema not defined when stored in the data lake
- Big data analytics, text analysis, ML
- Schema on read
- Data Warehouse
-
Object vs. Block Store
- Object storage
- S3 is used for object storage: highly scalable and available
- Store structured, unstructured and semi structured data
- Websites, mobile apps, archive, analytics applications
- Storage via a web service
- File storage
- EFS is used for file storage: shared file systems
- Content repositories, development environments, media stores, user home directories
- Block storage
- EBS attached to EC2 instances, EFS: volume type choices
- Redshift, Operating Systems, DBMS installs, file systems
- HDD: throughput intensive, large I/O, sequential I/O, big data
- SSD: high I/O per second, transaction, random access, boot volumes
- Object storage
-
Data Storage Lifecycle
- Persistent data
- OLTP and OLAP
- DynamoDB, RDS, Redshift
- Transient data
- Elasticache, DAX
- Website session info, streaming gaming data
- Archive data
- Retained for years, typically regulatory
- S3 Glacier (can combine with Vault Lock which allows you to easily deploy and enforce compliance controls for individual S3 Glacier vaults with a vault lock policy)
- Persistent data
-
Data Access Retrieval and Latency
- Retrieval speed
- Near-real time
- Streaming data with near-real time dashboard display
- Cached data
- Elasticache
- DAX
- Uses write-through cache
- Near-real time
- Retrieval speed
-
Different Approaches to Data Management
- Data Lake
- Store any data
- Store raw data
- Use for analytics - dashboards, visualizations, big data, real-time analytics, machine learning
- Data Warehouse
- Centralized data repository for BI and analysis
- Access the centralized data using BI tools, SQL clients, and other analytics apps
- Data Optimization
Data Lake Data Warehouse Any kind of data from IoT devices, social media, sensors, mobile app, relational, text Data Relational data with corresponding tables defined in the warehouse Schema-on-read: Schema is constructed by analyst or system when retrieved Schema Schema-on-write: defined based on knowledge of the data to load Raw data from many disparate sources Data Format Data is carefully managed and controlled, predefined schema Uses low-cost object storage Storage Costly with large data volumes =Change configuration as needed at any time Agility Configuration (schema/table structure) is fixed Machine learning specialists, data scientists, business analysts Users Management, business analysts Machine learning, data discovery, analytics applications, real-time streaming visualizations Applications Visualizations, business intelligence reporting - Data Warehouse
- Data warehouse is optimized to store relational data from transactional systems with schema-on-write
- Data lake stores all types of data: relational data and non-relational data from IoT devices, mobile apps, social media, etc. with schema-on-read
- Redshift Node types
- Node type defines CPU, memory, storage capacity and drive type
- Other compute node considerations
- Redshift distributes and executes your queries in parallel across all of your compute nodes
- Increase performance by adding compute nodes
- Clusters with more than one compute node, Redshift mirrors data on each node to another node, making data durable
- When nodes are added, Redshift deploys and load balances for you
- Can purchase reserved nodes
- Compute node data distribution optimization
- Efficient parallel processing accross your compute nodes
- Three distribution modes
- Key, All, Even
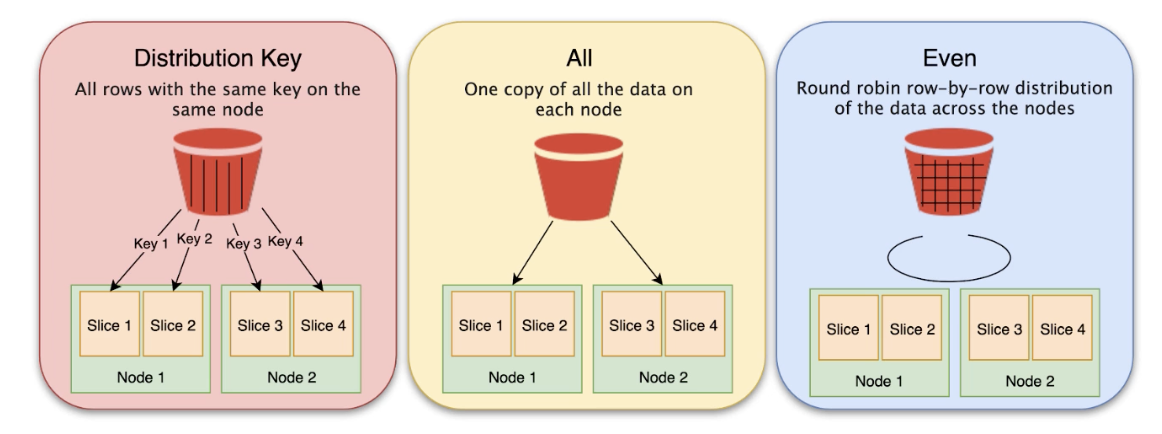
- Use cases:
- Key: Rows are distributed according to the values in one column. The leader node will place matching values on the same node slice and matching values from the common columns or physically stored together. Used for large joins across a particular column
- Even: Distributes the rows across the slices in a round robin fashion. Steps through each individual slice and keep assigning new data to each slice in a circular manner. Used for small tables that don’t participate in joins and don’t change often
- All: A copy of the entire table is distributed to every node that ensures that every row is co-located for every join that the table participates in the all distribution multiplies the storage required by the number of nodes in the cluster. Use for small tables that are updated infrequently and are not updated extensively
- Auto: Automatically assigned
- Compute node data distribution optimization
- Data Lake
-
-
Select appropriate data layout, schema, structure, and format
-
DynamoDB Partition Keys and Burst/Adaptive Capacity
- Optimal data distribution using DynamoDB partition keys
- Ensure uniform activity across all logical partition keys in the table and its secondary indexes
- Burst/Adaptive capacity: automatically enabled
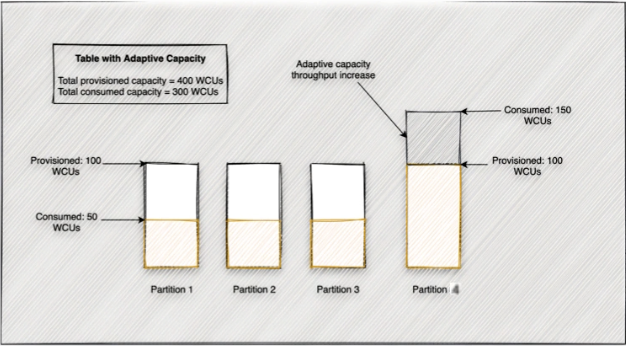
- Allows DynamoDB to run your imbalanced workloads
- “hot” partitions receive more reads/writes than other partitions and can lead to throttling
- Adaptive capacity automatically and instantly increases the throughput capacity for hot partitions
- Allows DynamoDB to run your imbalanced workloads
- Optimal data distribution using DynamoDB partition keys
-
Redshift Sort Keys
- Sort key definition
- When you load your data the rows are sorted in sorted order
- Sort key column info is passed to the query planner, which uses the info to build plans that benefit from that sort information
- Compound or Interleaved Sort Key
- When query predicates use a prefix, which is a subset of the sort key column in order, a compound sort key is more efficient
- Interleaved sort keys weight each column in the sort key equally; query predicates can use any subset of the columns that make up the sort key, in any order
- Sort key definition
-
Redshift
COPYCommandCOPYcommand is the most efficient way to load a Redshift table- Read from multiple data files or multiple data streams simultaneously
- Redshift assigns the workload to the cluster nodes and loads the data in parallel, inclduing sorting the rows and distributing data across node slices
- Note: Can’t
COPYinto Redshift Spectrum tables
- After ingestion or deletion, use
VACUUMcommand to reorganize your data in your tables
-
Redshift Compression Types
- Compression encoding defines the type of compression that is applied to a column, as rows are added to a table
- If you don’t specify a compression type at table creation or alter time Redshift applies this logic
- Columns that are sort keys get
RAWcompression - Columns that are
BOOLEAN,REALorDOUBLE PRECISIONgetRAWcompression - Columns that are
SMALLINT,INTEGER,BIGINT,DECIMAL,DATE,TIMESTAMP, orTIMESTAMPTZgetAZ64compression - Columns that are
CHARorVARCHARgetLZOcompression
- Columns that are sort keys get
-
Primary Key and Foreign Key Constraints
- Informational only, not enforced by Redshift but used to give more efficient query plans
- Query planner uses primary and foreign keys in some statistical computations to order large numbers of joins, and to eliminate redundant joins
-
-
Define data lifecycle based on usage patterns and business requirements
-
Data Lifecycle
- S3 Data Lifecycle
- Lifecycle policies
- S3 replication - business that require data to be distributed accross accounts or regions
- Database backups
- Redshift, RDS, DynamoDB
- S3 Data Lifecycle
-
S3 Data Lifecycle
Storage Class Intended Use S3 Standard Frequently accessed data S3 Standard-IA Long-lived, infrequently accessed data S3 Intelligent Tiering Long-lived data with changing or unknown access patterns S3 One-Zone-IA Long-lived, infrequently accessed non-critical data S3 Glacier Long-term data archiving with retrieval times of minutes to hours tolerated S3 Glacier Deep Archive Archive of rarely accessed data with retrieval time of 12 hours as default - Storage classes
- Help reduce cost of data storage
- Allow you to choose the right storage tier based on the characteristics of your data
- Storage classes
-
S3 Lifecycle Policies
- Lifecycle rules configuration configures S3 when to transition objects to another Amazon S3 storage class
- Define rules to move objects from one storage class to another
- Transition between storage classes uses a waterfall model
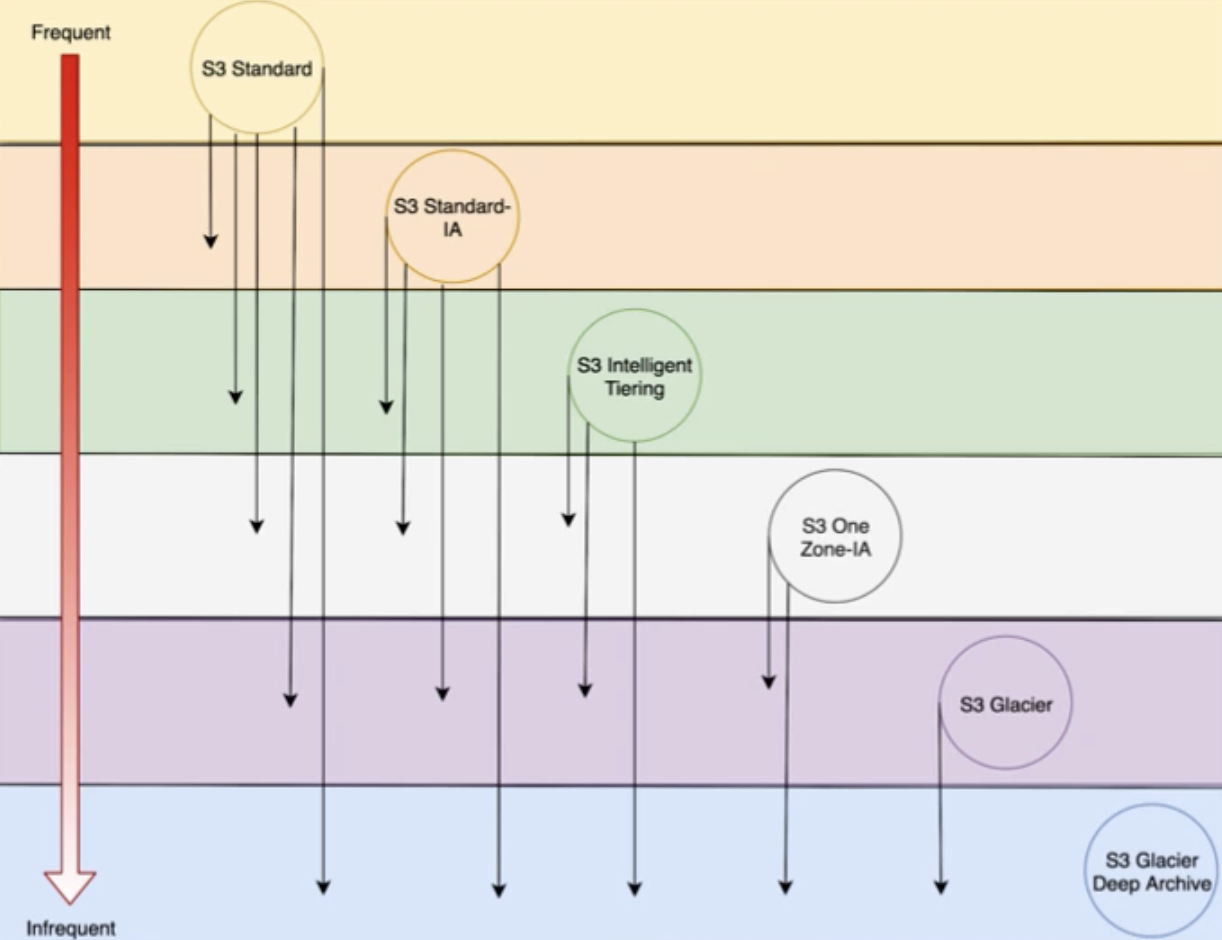
- Encrypted objects stay encryped throughout their lifecycle
- Transition to S3 Glacier Deep Archive is a one way trip (use the restore operation to move object from Deep Archive)
-
S3 Replication
- Replication copies your S3 objects automatically and asychronously across S3 buckets
- Use Cross-Region Replication (CRR) to copy objects across S3 buckets in different regions
- Use Same-Region Replication (SRR) to copy objects across S3 buckets in the same region
- Use cases:
- Compliance requirements - physically seperated backups
- Latency - house replicated object copies local to your users
- Operational efficiency - applications in different regions analyzing the same object data
- Replication copies your S3 objects automatically and asychronously across S3 buckets
-
Database Backups
- Database management requires backups on a given frequency according to your requirements
- Restores from backups
- Redshift stores snapshots internally on S3
- Snapshots are point-in-time backups of your cluster
- DynamoDB allows for backup on demand
- Backup and restore have no impact on the performance of your tables
- RDS performs automated backups of your database instance
- Can recover to any point-in-time
- Can perform manual backups using database snapshots
-
-
Determine the appropriate system for cataloging data and managing metadata
- Hive records your data metastore information in a MySQL database housed on the master node file system
- Hive metastore describes the table and the underlying data on which it is built
- Partition names
- Data types
- At cluster termination, the master node shuts down
- Local data is deleted since master node file system is on ephemeral storage
- To maintain a persistent metastore, create an external metastore
- two options
- Glue data catalogue as Hive metastore
- External MySQL or Aurora Hive metastore
- two options
- Hive metastore describes the table and the underlying data on which it is built
-
Glue Data Catalogue as Hive Metastore
- When you need a persistent metastore or a shared metastore used by different clusters, services, applications or AWS accounts
- Metadata repository across many data sources and date formats
- EMR, RDS, Redshift, Redshift Spectrum, Athena, application code compatible with Hive metastore
- Glue crawlers infer the schema from your data objects in S3 and store the associated metadata in the Data Catalogue
- Limitations
- Hive transactions are not supported
- Column level statistics are not supported
- Hive authorizations are not suported, use Glue resource-based policies
- Cost-based optimization in Hive is not supported
- Temporary tables are not support
-
External RDS Hive Metastore
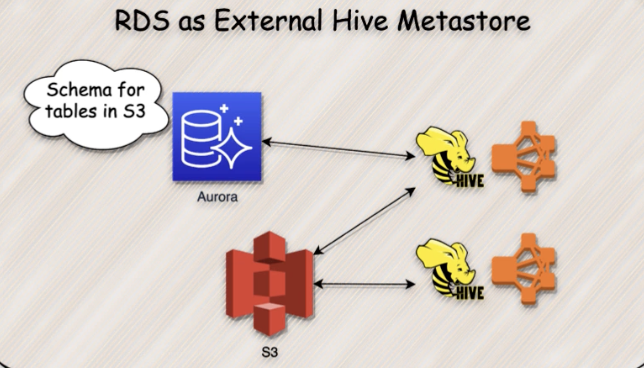
- Override the default for the metastore in Hive, use external database location
- RDS MySQL or Aurora instance
- Hive cluster runs using the metastore located in Amazon RDS
- Start all additional Hive clusters that share this metastore by specifying the RDS metastore location
- RDS replication is not enabled by default, configure replication to avoid any data loss in the vent of failure
- Hive does not support and also does not prevent concurrent writes to metastore tables
- When sharing metastore information between two clusters, do not write to the same metastore table concurrently, unless writing to different metastore table partitions
-
Populating the Glue Catalogue
- Holds references to data used as sources and targets in your Glue (ETL) jobs
- Catalog your data in the Glue Data Catalogue to use when creating your data lake or data warehouse
- Holds information on the location, schema, and runtime metrics of your data
- Use this information to create ETL jobs
- Information stored as metadata tables, with each table describing a single data store
- Ways to add metadata tables to your Data Catalogue
- Glue crawler
- AWS console
- CreateTable Glue API call
- CloudFormation templates
- Migrate an Apache Hive metastore
- Steps to Populate the Glue Data Catalogue
- Four steps
- Classify your data by running a crawler
- Custom classifiers
- Built-in classifiers
- Crawler connects to the data store
- Crawler infers the schema
- Crawler writes metadata to the Data Catalogue
- Classify your data by running a crawler
- Four steps
-
Glue Ecosystem
- Categorizes, cleans, enriches, and moves your data reliably between various data stores
- Several AWS services natively support querying data sources via the unified metadata repository of the Glue Data Catalogue
- Athena
- Redshift
- Redshift Spectrum
- EMR
- RDS
- Any application compatible with the Apache Hive metastore
- Hive records your data metastore information in a MySQL database housed on the master node file system
Processing
-
Determine appropriate data processing solution requirements
-
Glue ETL on Apache Spark
- Use Glue when you don’t need or want to pay for an EMR cluster
- Glue generates an Apache Spark (PySpark or Scala) script which you can edit
- Glue runs in a fully managed Apache Spark environment
- Spark has 4 primary libraries
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
- Cluster Managers
- Yarn
- Mesos
- Standalone Scheduler
- Spark has 4 primary libraries
- Use Glue when you don’t need or want to pay for an EMR cluster
-
EMR Cluster ETL Processing
- More flexible and powerful than Spark
- Can use Spark on EMR, but there are other options
- More flexible and powerful than Spark
-
EMR Integration
- Integrates with the following data stores
- Use S3 as an object store for Hadoop
- HDFS on the Core nodes instance storage
- Directly access and process data in DynamoDB
- Process data in RDS
- Use
COPYcommand to load data in parallel into Redshift from EMR - Integrates with S3 Glacier
- Integrates with the following data stores
-
Kinesis ETL Processing
- Use Kinesis Analytics to gain real-time insights into your streaming data
- Query data in your stream or build streaming applications using SQL or Flink
- Use for filtering, aggregation, and anomaly detection
- Preprocess your data with Lambda
- Use Kinesis Analytics to gain real-time insights into your streaming data
-
Glue ETL Jobs - Structure
- A Glue job defines the business logic that performs the ETL work in AWS Glue
- Glue runs your script to extract data from your sources, transform the data, and load it into your targets
- Glue triggers can start jobs based on a schedule or event, or on demand
- Monitor your job runs to get runtime metrics, completion status, duration, etc.
- Based on your source schema and target location or schema, the Glue code generator automatically creates an Apache Spark API (PySpark) script
- Edit the script to customize to your requirements
- A Glue job defines the business logic that performs the ETL work in AWS Glue
-
Glue ETL Jobs - Types
- Glue outputs file formats such as JSON, CSV, ORC, Parquet, and Avro
- Three types of Glue jobs
- Spark ETL job
- Executed in managed Spark environment, processes data in batches
- Streaming ETL job: (like a Spark ETL job, but works with data streams) uses the Apache Spark Structured Streaming framework
- Python shell job: Schedule and run tasks that don’t require an Apache Spark environment
- Spark ETL job
-
Glue ETL Jobs - Transforms
- Glue has built-in transforms for processing data
- Call from within your ETL script
- In a DynamicFrame (an extension of an Apache Spark SQL DataFrame), your data passes from transform to transform
- Built-in transform types (subset)
- ApplyMapping: maps source DynamicFrame columns and data types to target DynamicFrame columns and data types
- Filter: selects records from a DynamicFrame and returns a filtered DynamicFrame
- Map: applies a function to the records of a DynamicFrame and returns a transformed DynamicFrame
- Relationalize: converts a DynamicFrame to a relational (rows and columns) form
-
Glue ETL Jobs - Triggers
- A trigger can start specified jobs and crawlers
- On demand, based on a schedule, or based on a combination of events
- Add a trigger via the Glue console, the AWS CLI or the Glue API
- Activate or deactivate a trigger via the Glue console, the CLI or the Glue API
- A trigger can start specified jobs and crawlers
-
Glue ETL Jobs - Monitoring
- Glue produces metrics for crawlers and jobs for monitoring
- Statistics about the health of your environment
- Statistics are written to the Glue Data Catalogue
- Use automated monitoring tools to watch Glue and report problems
- CloudWatch events
- CloudWatch logs
- CloudTrail logs
- Profile your Glue jobs using metrics and visualize on the Glue and CloudWatch consoles to identify and fix issues
- Glue produces metrics for crawlers and jobs for monitoring
-
EMR Components
- EMR is built on clusters of EC2 instances
- The EC2 instances are called nodes, all of which have roles (or node type) in the cluster
- EMR installs different software components on each node type, defining the node’s role in the distributed architecture of EMR
- Three types of nodes
- Master node: manages the cluster, running software components to coordinate the distribution of data and tasks across other nodes for processing
- Core node: has software components that run tasks and store data in the HDFS on your cluster
- Task node: node with software components that only runs tasks and does not store data in HDFS
- EMR is built on clusters of EC2 instances
-
EMR Cluster - Work
- Options for submitting work to your EMR cluster
- Script the work to be done as functions that you specify in the steps you define when you create a cluster
- This approach is used for clusters that process data then terminate
- Build a long-running cluster and submit steps (containing one or more jobs) to it via the console, the EMR API, or the AWS CLI
- This approach is used for clusters that process data continuously or need to remain available
- Create a cluster and connect to the master node and/or other nodes as required using SSH
- This approach is used to perform tasks and submit queries, either scripted or interactively, via the interfaces of the installed applications
- Script the work to be done as functions that you specify in the steps you define when you create a cluster
- Options for submitting work to your EMR cluster
-
EMR Cluster - Processing Data
- At launch time, you choose the frameworks and applications to install to achieve your data processing needs
- You submit jobs or queries to installed applications or run steps to process data in your EMR cluster
- Submitting jobs/steps to installed applications
- Each step is a unit fo work that has instructions to process data by software installed on the cluster
- Submitting jobs/steps to installed applications
-
EMR Cluster - Lifecycle
- Provisions EC2 instances of the cluster
- Runs bootstrap actions
- Installs applications such as Hive, Hadoop, Sqoop, Spark
- Connect to the cluster instances; cluster sequentially runs any steps that specified at creation; submit additional steps
- After steps complete the cluster waits or shuts down, depending on config
- When all instances are terminated, the cluster moves to
COMPLETEDstate
-
EMR Architecture - Storage
- Architected in layers
- Storage: file systems used by the cluster
- HDFS: distributes the data it stores across instances in the cluster(ephemeral)
- EMRFS: directly access data stored in S3 as if it were a file system like HDFS
- Local file system: EC2 locally connected disk
- Storage: file systems used by the cluster
- Architected in layers
-
EMR Architecture - Cluster Management
- YARN
- Centrally manages cluster resources
- Agent on each node that keeps the cluster healthy and communicates with EMR
- EMR defaults to scheduling YARN jobs so that jobs won’t fail when task nodes running on spot instances are terminated
- YARN
-
EMR Architecture - Cluster Management
- Framework layer that is used to process and analyze data
- Different frameworks available
- Hadoop MapReduce
- Parallel distributed applications that use Map and Reduce functions
- Map function maps data to sets of key-value pairs
- Reduce function combines the key-value pairs and processes the data
- Parallel distributed applications that use Map and Reduce functions
- Spark
- Cluster framework and programming model for processing big data workloads
- Hadoop MapReduce
- Different frameworks available
- Framework layer that is used to process and analyze data
-
Lake Formation
- Loading data and monitoring data flows
- Setting up partitions
- Encryption and managing keys
- Defining transformation jobs and monitoring them
- Built on top of Glue
-
Data Pipeline
- Data pipeline lets you schedule tasks for processing your big data
- Destinations include S3, RDS, DynamoDB, Redshift and EMR
- Manage task dependencies
- Precondition checks
- Data sources may be on-premises
-
-
Design a solution for transforming and preparing data for analysis
-
Optimizing EMR
- Instance type
- Ways to add EC2 instances to your cluster
- Instance Groups
- Manually add instances of the same type to existing core and task instance groups
- Manually add a task instance group, can use a different instance type
- Automatic scaling for an instance group based on the value of a CloudWatch metric specified by you
- Instance Fleets
- Add a single task instance fleet
- Change the target capacity for On-Demand and Spot Instances for existing core and task instance fleets
- Instance Types
- Plan your capacity
- Run a test cluster using a representative sample data set and monitor the node utilization
- Calculate instance capacity and compare the value against the size of your data
- Master node doesn’t require high computation capacity
- Most EMR cluster can run on m5.xlarge or m4.xlarge
- Plan your capacity
- Instance Groups
- Ways to add EC2 instances to your cluster
- Instance configuration
- Persistent EMR cluster (e.g. Data Warehouse)
- Master and core instance groups as on-demand instances
- Task instance group as spot instances
- Cost-driven workloads: low cost, partial work loss OK
- Transient clusters
- Run all groups, master, core and task instance groups as spot instances
- Data-critical workloads: low cost, partial work loss not OK
- Master and core instance groups as on-demand, task instance groups as spot
- Test environment: all instance groups on spot
- Persistent EMR cluster (e.g. Data Warehouse)
- HDFS capacity
- To calculate the storage allocation for your cluster consider the following
- Number of EC2 instances used for core nodes
- Capacity of the EC2 instance store for the instance type used
- Number and size of EBS volumes attached to core nodes
- Replication factor: how each data block is stored in HDFS for RAID-like redundancy
- 3: for cluster of 10 or more core nodes
- 2: for cluster of 4-9 core nodes
- 1: for cluster of 3 or fewer nodes
- HDFS capacity for your cluster
- For each core node, add instance store volume capacity to EBS storage capacity
- Multiply by the number of core nodes, then divide the total by the replication factor
- To calculate the storage allocation for your cluster consider the following
- Dynamic sizing
- Dynamically scales nodes in your cluster based on demand
- On scale down of task nodes on a running cluster expect a short delay for any running Hadoop to decommission
- On scale down fo core nodes EMR waits for HDFS to decommission to protect your data
- Changing configuration improperly on a cluster with high load can seriously degrade cluster performance
- Dynamically scales nodes in your cluster based on demand
- Instance fleets vs. uniform instance groups
- Choice applies to all nodes for the lifetime of the cluster
- Instance fleets and instance groups cannot coexist in a cluster
- Instance fleets
- Each node type has a single instance fleet; task instance fleet is optional
- Up to 5 instance types (if using allocation strategy, up to 15 instance types on task instance fleets), which can be provisioned as On-Demand and Spot Instances
- Mix of specified instance types to reach target capacities: On-Demand and Spot Instances
- Core and Task instance fleets: assign a target capacity for On-Demand Instances, and another for Spot Instances
- Instance Group
- Simplified, up to 50 instance groups:
- 1 master instance group containing 1 EC2 instance
- Core instance group containing one or more EC2 instance, up to 48 optional task instance groups
- Scale each instance group by adding and removing EC2 instances manually, or set up automatic scaling
- Simplified, up to 50 instance groups:
- Run multiple steps in parallel
- Allows for parallel processing and greater speed
- Considerations
- Using EMR automatic scaling to scale up/down based on the YARN resources to prevent resource contention
- Running multiple steps in parallel requires more memory and CPU utilization from the master node than running one step at a time
- Use YARN scheduling features such as FairScheduler or CapacityScheduler to run multiple steps in parallel
- If you run out of resources because the cluster is running too many concurrent steps, manually cancel any running steps to free up resources
- EMR - AWS integration
- AWS VPC to configure the virutal network in which you launch your instances
- S3 to store input and output data
- CloudWatch to monitor cluster performance and configure alarms
- IAM to configure permissions
- CloudTrail to audit requests made to the service
- Data Pipeline to schedule and start your clusters
- Instance type
-
Batch versus Streaming ETL Services
- Based on your use case, you need to select the best tool or service
- Batch or Streaming ETL
- Batch processing model
- Data is collected over a period of time, then run through analytics tools
- Time consuming, design for large quantities of information that aren’t time-sensitive
- AWS services used for batch processing
- Glue batch ETL
- Schedule ETL jobs to run at a maximum of 5-minute intervals
- Process micro-batches
- Serverless
- EMR batch ETL
- Use Impala or Hive to process batches of data
- Cluster of servers
- Glue batch ETL
- Streaming processing model
- Data is processed in a stream, a record at a time or in micro-batches
- Fast, designed for information that’s needed immediately
- AWS services used for stream processing
- Lambda
- Read records from your data stream, runs functions synchronously
- Frequently used with Kinesis
- Serverless
- Kinesis
- Use the KCL, Kinesis Analytics, Kinesis Firehose to process your data
- Serverless
- EMR Streaming ETL
- Use Spark Streaming to build your stream processing ETL application
- Cluster of servers
- Lambda
- Batch processing model
-
-
Automate and operationalize data processing solutions
-
Orchestration of Workflows
- Coordinating your ETL jobs across Glue, EMR, and Redshift
- With orchestration, you can automate each step in your workflow
- Retry on errors
- Find and recover jobs that fail
- Track the steps in your workflow
- Build repeatable workflows
- Respond to state changes on EMR cluster
- Using CloudWatch metrics to manage your EMR cluster
- View and monitor your EMR cluster
- Leverage EMR API calls in CloudTrail
- With orchestration, you can automate each step in your workflow
- Coordinating your ETL jobs across Glue, EMR, and Redshift
-
Respond to State Changes on EMR Cluster
- Trigger create, terminate, scale cluster, run Spark, Hive or Pig workloads based on Cluster state changes
- EMR CloudWatch events support notify you of state changes in your cluster
- Respond to state changes programmatically
- EMR CloudWatch events
- Cluster State Change
- Instance Group and Instance Fleet State Change
- Step State Change
- Auto Scaling State Change
- Create filters and rules to match events and route them to SNS topics, Lambda functions, SQS queues, Kinesis Streams
- EMR CloudWatch events
-
Use CloudWatch Metrics to Manage EMR Cluster
- EMR metrics updated every 5 minutes, collected and pushed to CloudWatch
- Non-configurable metric timing
- Metrics archived for two weeks then discarded
- EMR metrics uses
Use Case Metrics Track progress of cluster `RunningMapTasks`, `RemainingMapTasks`, `RunningReduceTasks`, and `RemainingReduceTasks` metrics Detect idle clusters `IsIdle` metric tracks if a cluster is live, but not currently running tasks. Set an alarm to fire when the cluster has been idle for a given period of time Detect when a node runs out of storage `HDFSUtilization` metric gives the percentage of disk space currently used. If it rises above an acceptable level for your application, such as 80% of capacity used, you take action to resize your cluster and add more core nodes
- EMR metrics updated every 5 minutes, collected and pushed to CloudWatch
-
View and Monitor EMR Cluster
- EMR has several tools for retrieving information about your cluster
- Console, CLI, API
- Hadoop web interfaces and logs on Master node
- Use monitoring services like CloudWatch and Ganglia to track the performance of your cluster
- Application history available through persistent application UIs for Spark history Server, persistent YARN timeline server, and Tez user interfaces
- EMR has several tools for retrieving information about your cluster
-
Leverage EMR API Calls in CloudTrail
- CloudTrail holds a record of actions taken by users, roles or an AWS service in EMR
- Captures all API calls for EMR as events
- Enable continuous delivery of CloudTrail events to an S3 bucket
- Determine the EMR request, the IP address from which the request, when it was made, and additional details
- CloudTrail holds a record of actions taken by users, roles or an AWS service in EMR
-
Orchestrate Spark and EMR workloads using Step Functions
- Directly connect Step Functions to EMR
- Create data processing and analysis workflows with minimal code and optimize cluster utilization
- Easy visualizations
- Directly connect Step Functions to EMR
-
Workflows in Glue
- Use workflows to create and visualize complex ETL tasks involving multiple crawlers, jobs and triggers
- Manages the execution and monitoring of all components
- Glue console provides a visual representation of a workflow as a graph
- Chain interdependent jobs and crawlers
- Event triggers fired by both jobs or crawlers, and can start both jobs and crawlers
- Views
- Static: shows the design of the workflow
- Dynamic: run time view, shows the latest run information for each of the jobs and crawlers
-
Orchestration of Glue and EMR Workflows
- Several ways to operationalize Glue and EMR workflows
- Glue workflows
- A workflow is a grouping of set of jobs, crawlers, and triggers in GLue
- Can design a complex multi-job (ETL) sequence that Glue can execute and track as single entity
- Create workflows using the AWS Console or the Glue API
- Console lets you to see the components and flow of a workflow with a graph
- A workflow is a grouping of set of jobs, crawlers, and triggers in GLue
- Automate workflow using Lambda
- Use Lambda functions and CloudWatch Events to orchestrate your workflow
- Start your workflow with Lambda trigger
- Use CloudWatch Events to trigger other steps in your workflow
- Use Lambda functions and CloudWatch Events to orchestrate your workflow
- Step Functions with Glue
- Serverless orchestration of your Glue steps
- Easily integrates with EMR steps
- Step Functions directly with EMR
- Use Step Functions to control all steps in your EMR cluster operation
- Also integrate other AWS services into your workflow
- Glue workflows
- Several ways to operationalize Glue and EMR workflows
-
Analysis and Visualization
-
Determine the operational characteristics of the analysis and visualization solution
-
Purpose-Built Analytics Services
- Choose the correct approach and tool for your analytics problem
- Know the AWS purpose-built analytics services
- Athena
- Elastic Search
- EMR
- Kinesis - Data Streams, Firehose, Analytics, Video Streams
- Redshift
- MSK
- Also know where to use
- S3
- EC2
- Glue
- Lambda
-
Appropriate Analytics Service
Category Use Case Analytics Service Analytics Interactive analytics Athena Big data processing EMR Data Warehousing Redshift Real-time analytics Kinesis Operational analytics Opensearch Dashboards and visualizations QuickSight Data Movement Real-Time data movement Managed Streaming for Kafka (MSK), Kinesis Data Streams, Kinesis Data Firehose, Kinesis Data Analytics, Kinesis Video Streams, Glue Data Lake Object storage S3, Lake Formation Backup and archive S3 Glacier, AWS Backup Data catalog Glue, Lake Formation Third-part data AWS Data Exchange Predictive Analytics/ML Frameworks and interfaces AWS Deep Learning AMis Platform services SageMaker -
Use Cases - Data Warehousing
- Without unnecessary data movement use SQL to query structured and unstructured data in your data warehouse and data lake
- Redshift
- Query petabytes of structured, semi-structured, and unstructured data
- Data Warehouse
- Operational Database
- S3 Data Lake using Redshift Spectrum
- Save query results to S3 data lake using common formats such as Parquet
- Analyze using other analytics services such as EMR, Athena, and SageMaker
- Query petabytes of structured, semi-structured, and unstructured data
-
Use Cases - Big Data Processing
- Process large amounts of data in your data lake
- EMR
- Data Engineering
- Data Science
- Data Analytics
- Spin up/spin down clusters for short running jobs, such as ingestion clusters, and pay by the second
- Automatically scale long-running clusters, such as query clusters, that are highly available
-
Use Cases - Real Time Analytics with MSK
- Data collection, processing, analysis on streaming data loaded directly into data lake, data stores, analytics services
- Uses Apache Kafka to process streaming data
- To and from Data Lake and databases
- Power machine learning and analytics applications
- MSK provisions and runs Apache Kafka cluster
- Monitors and replaces unhealthy nodes
- Encrypts data at rest
-
Use Cases - Real Time Analytics with Kinesis
- Ingest real-time data such as video, audio, application logs, website clickstreams, and IoT data
- Kinesis
- Ingest data in real-time for machine learning and analytics
- Process and analyze data as it streams to your data lake
- Process and respond in real-time on your data stream
- Ingest data in real-time for machine learning and analytics
-
Use Cases - Operational Analytics
- Search, filter, aggregate, and visualize your data in near real-time
- Opensearch
- Application monitoring, log analytics, and clickstream analytics
- Managed Kibana
- Alerting and SQL querying
- Application monitoring, log analytics, and clickstream analytics
-
-
Usage patterns, performance and cost
-
Glue
- Usage:
- Crawl your data and generate code to execute, includes data transformations and loading
- Integrate with services like Athena, EMR, and Redshift
- Generates customizable, reusable, and portable ETL code using Python
- Cost:
- Hourly rate, billed by the minute, for crawler and ETL jobs
- Glue Data Catalogue: pay a monthly fee for storing and accessing your metadata
- Performance:
- Scale-out Apache Spark environment to load data to target data store
- Specify the number of Data Processing Units (DPUs)
- Durability and Availability:
- Glue leverages the durability of the data stores to which you connect
- Provides job status and pushes notifications to CloudWatch events
- Use SNS notifications from CloudWatch events to notify of job failures or success
- Scalability and Elasticity:
- Runs on top of Apache Spark for transformation job scale-out execution
- Interfaces:
- Crawlers scan many data store types
- Bulk import Hive metastore into Glue Data Catalog
- Anti-Patterns:
- Streaming data, unless Spark Streaming
- Heterogeneous ETL job types, use EMR
- Usage:
-
Lambda
- Run code without provisioning or managing servers
- Usage:
- Execute code in response to triggers such as changes in data, changes in system state, or actions by users
- Real-time file processing and stream
- Process AWS Events
- Replace CRON
- Perform ETL jobs
- Note: S3 has the ability to trigger a Lambda function whenever a new object appears in a bucket
- Cost:
- Charged by the number of requests to functions and code execution time
- $0.20 per 1,000,000 requests
- Performance:
- Process events within milliseconds
- Latency higher for cold start
- Retains a function instance and reuses it to serve subsequent requests, versus creating new copy
- Durability and Availability:
- No maintenance windows or scheduled downtime
- On failure, Lambda synchronously responds with an exception
- Asynchronous functions are retried at least 3 times
- Scalability and Elasticity:
- Scales automatically with no limits with dynamic capacity allocation
- Interfaces:
- Trigger Lambda with AWS service events
- Respond to CloudTrail audit log entries as events
- Anti-Patterns:
- Long-running applications: 900 sec runtime
- Dynamic websites
- Stateful applications
- Lambda + Kinesis
- Your Lambda code receives an event with a batch of stream records
- You specify a batch size when setting up the trigger (up to 10,000 records)
- Too large a batch size can cause timeouts
- Batches may also be split beyond Lambda’s payload limit (6 MB)
- Lambda polls your Kinesis streams for new activity
- Lambda will retry the batch until it succeeds or the data expires
- This can stall the shard if you don’t handle errors properly
- Use more shards to ensure processing isn’t totally held up by errors
- Lambda processes shard data synchronously
- Your Lambda code receives an event with a batch of stream records
-
EMR
- Usage:
- Reduces large processing problems and data sets into smaller jobs and distributes them across many compute nodes in a Hadoop cluster
- Log processing and analytics
- Large ETL data movement
- Ad targeting, click stream analytics
- Predictive analytics
- Cost:
- Pay for the hours the cluster is up
- EC2 pricing options (On-Demand, Reserved, and Spot)
- EMR price is in addition to EC2 price
- Performance
- Driven by type/number of EC2 instances
- Ephemeral or long-running
- Durability and Availability:
- Starts up with a new node if core node fails
- Won’t replace nodes if all nodes in the cluster fail
- Monitor for node failure through CloudWatch
- Scalability and Elasticity:
- Resize your running cluster: add core nodes, add/remove task nodes
- Interfaces:
- Tools on top of Hadoop: Hive, Pig, Spark, HBase, Presto
- Kinesis Connector: directly read and query data from Kinesis Data Streams
- Anti-Patterns:
- Small data sets
- ACID transactions; RDS is a better choice
- Usage:
-
Kinesis
- Usage:
- Move data from producers and continuously process it to transform before moving to another data store; drive real-time metrics and analytics
- Real-time data analytics
- Log intake and processing
- Real-time metrics and reporting
- Kinesis Analytics can only monitor streams from Kinesis, but both data streams and Firehose are supported
- Kinesis Analytics must have a stream as its input, and a stream or Lambda function as its output
- If a record arrives late to your application during stream processing, it is written to the error stream
- Kinesis Data Analytics provisions capacity in the form of Kinesis Processing Units (KPU). A single KPU provides you with the memory (4 GB) and corresponding computing and networking. The default limit for KPUs for your application is eight.
- Video/Audio processing
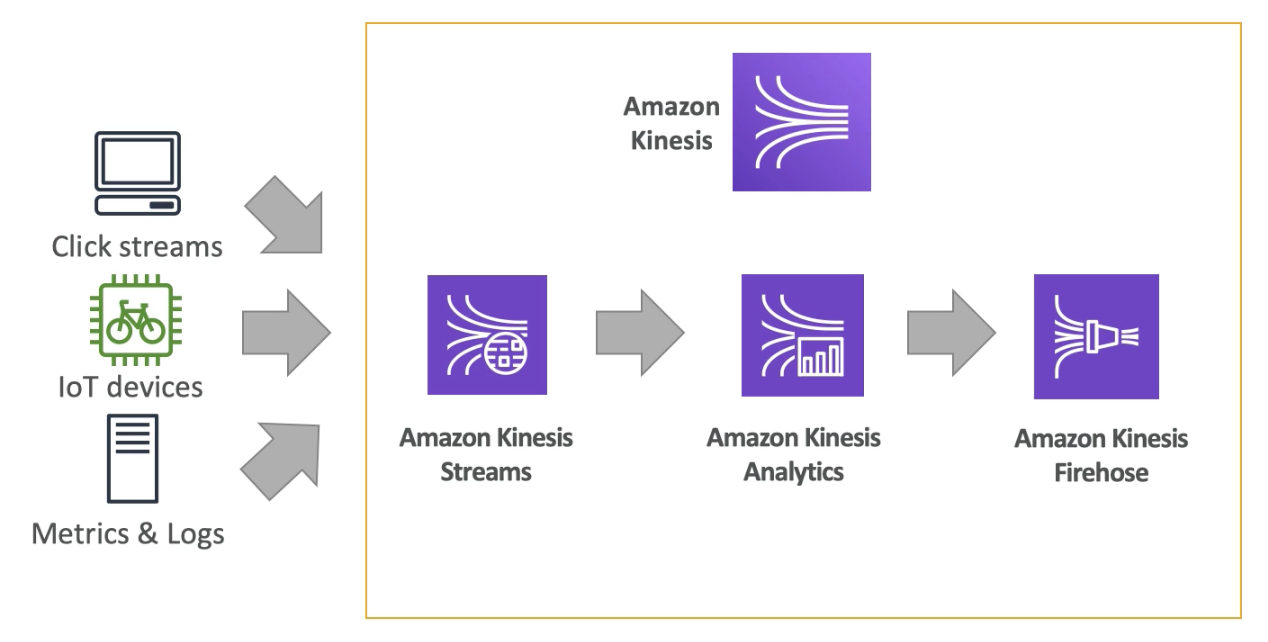
- Cost
- Pay for the resources consumed
- Data Streams hourly price per/shard
- Charge for each 1 million
PUTtransactions
- Performance
- Data Streams: throughput capacity by number of shards
- Provision as many shards as needed
- Durability and Availability:
- Near real-time
- Synchronously replicates data across three AZs
- Highly available and durable due to config of multiple AZs in one Region
- Use cursor in DynamoDB to restart failed apps
- Resume at exact position in the stream where failure occurred
- Scalability and Elasticity:
- Use API calls to automate scaling, increase or decrease stream capacity at any time
- Interfaces:
- Two interfaces: input (KPL, agent, PUT API), output (KCL)
- Kinesis Storm Spout: read form a Kinesis stream into Apache Storm
- RANDOM_CUT_FOREST:
- SQL function used by anomaly detection on numeric columns in a stream
- They’re especially proud of this because they published a paper on it
- Anti-Patterns:
- Small scale consistent throughput
- Long-term data storage and analytics, Redshift, S3, or DynamoDB are better choices
- Usage:
-
DynamoDB
- Usage:
- Apps needing low latency NoSQL database able to scale storage and throughput or down without code changes or downtime
- Mobile apps and gaming
- Sensor networks
- Digital ad serving
- E-Commerce shopping carts
- Cost:
- Three components:
- Provisioned throughput capacity(per hour)
- Indexed data storage (per GB per month)
- Data Transfer in or out (per GB per month)
- Three components:
- Performance
- SSDs and limiting indexing on attributes provides high throughput and low latency
- Define provisioned throughput capacity required for your tables
- Durability and Availability:
- Protection against individual machine or facility failures
- DynamoDB Streams allows replication across regions
- Streams enables table data activity replicated across geographic regions
- Scalability and Elasticity:
- No limit to data storage, automatic storage allocation, automatic data partition
- Interfaces:
- REST API allows management and data interface
- DynamoDB select operation creates SQL-like queries
- Anti-Patterns:
- Port applications from relational databases
- Joins or complex transactions
- Large data with low I/O rate
- Blob data > 400kb, S3 is a better choice
- Usage:
-
Redshift
- Usage:
- Designed for OLAP using business intelligence tools
- Analyze sales data for multiple products
- Analyze ad impressions and clicks
- Aggregate gaming data
- Analyze social trends
- Cost:
- Charges based on the size and number of cluster nodes
- Backup storage > provisioned storage size and backups stored after cluster termination billed at standard S3 rate
- Performance:
- Columnar storage, data compression, and zone maps to reduce query I/O
- Parallelizes and distributes SQL operations to take advantage of all available resources
- Durability and Availability:
- Automatically detects and replaces a failed node in your data warehouse cluster
- Failed node cluster is read-only until replacement node is provisioned and added to the DB
- Cluster remains available on drive failure; Redshift mirrors your data across the cluster
- Backup to S3
- Automatic snapshots
- Limited to 1 AZ
- Scalability and Elasticity:
- With API change the number, or type, of nodes while cluster remains live
- Interfaces:
- JDBC and ODBC drivers for use with SQL clients
- S3, DynamoDB, Kinesis, BI tools such as QuickSight
- Anti-Patterns:
- Small data sets
- Online transaction processing
- Unstructured data
- Blob data, S3 is a better choice
- Analytics and Visualization:
- Two options:
- Query via AWS management console using the query editor, or via a SQL client tool
- Supports SQL client tools via JDBC and ODBC
- Using the Redshift API you can access Redshift data with web services-based applications, including AWS Lambda, AWS AppSync, SageMaker notebooks, and AWS Cloud9
- Query via AWS management console using the query editor, or via a SQL client tool
- Redshift Spectrum
- Query data directly from files on S3
- Need a Redshift cluster and a SQL client connected to your cluster to execute SQL commands
- Visualize data via QuickSight
- Cluster and data in S3 must be in the same region
- Two options:
- Integration with other services:
- You can load data from DynamoDB, EMR, EC2, Data Pipeline, DMS to Redshift using
COPY
- You can load data from DynamoDB, EMR, EC2, Data Pipeline, DMS to Redshift using
- Redshift Workload Management(WLM):
- It’s a way to help users prioritize workload by ensuring that short, fast running queries are not stuck behind long running slow queries.
- The way it works is by creating query queues at runtime according to service classes and configuration parameters for various types of cues are defined by those service classes.
- Concurrency Scaling:
- Automatically adds cluster capacity to handle increase in concurrent
READqueries - WLM queues manage which queries are sent to the concurrency scaling cluster
- Short Query Acceleration
- Prioritize short-running queries over longer-running ones
- Short queries run in a dedicated space, won’t wait in queue behind long queries
- Can be used in place of WLM queues for short queries
- Automatically adds cluster capacity to handle increase in concurrent
VACUUMcommand:VACUUM FULL: It will resort all rows and reclaimed space from deleted rows.VACUUM DELETE ONLY: which is the same as a full vacuum, except that it skips the sorting part. Just reclaims deleted row space and not actually resort it.VACUUM SORT ONLY: Resorts the table, but does not reclaim the space.VACUUM REINDEX: Used for re-initializing interleaved indexes
- Resizing Redshift Clusters:
- Elastic resize
- Quickly add or remove nodes of same type
- Cluster is down for a few minutes
- Tries to keep connection open across the downtime
- Limited to doubling or halving for some node types
- Classic resize
- Change node type and/or number of nodes
- Cluster is read-only for hours to days
- Snapshot, restore, resize
- Used to keep cluster available during a classic resize
- Copy cluster, resize new cluster
- Elastic resize
- Redshift Security concerns:
- Using a Hardware Security Module
- Must be a client and server certificate to configure a trusted connection between Redshift and the HSM
- If migrating an unencrypted cluster to an HSM-encrypted cluster, you must create the new encrypted cluster and then move data to it
- Defining access privileges for user or group
- Use the
GRANTorREVOKEcommands in SQL
- Use the
- Using a Hardware Security Module
- Usage:
-
Athena
- Usage:
- Interactive ad hoc querying for web logs
- Presto under the hood
- Serverless
- Query staging data before loading into Redshift (stays in S3)
- Sending AWS service logs to S3 for Analysis with Athena
- Integrate with Jupyter, Zepplin
- Integrate with QuickSight
- Can organize users/teams/apps/workloads into Workgroups
- Integrates with IAM, CloudWatch, SNS
- Each workgroup can have its own data history, data limits, etc.
- Cost:
- $5 per TB of query data scanned
- Save on per-query costs and get better performance by compressing, partitioning, and converting data into columnar formats
- Save LOTS of money by using columnar formats like ORC, Parquet
- Performance
- Compressing, partitioning, and converting your data into columnar formats
- Convert data to columnar formats like Parquet and ORC, allowing Athena to read only the columns it needs to process queries
- Durability and Availability:
- Executes queries using compute resources across multiple facilities
- Automatically routes queries if a particular facility is unreachable
- S3 is the underlying data store, gaining S3’s 11 9s durability
- Scalability and Elasticity:
- Serverless, scales automatically as needed
- Interfaces:
- Athena CLI, API via SDK, and JDBC
- QuickSight visualizations
- Anti-Patterns:
- Enterprise Reporting and Business Intelligence Workloads; Redshift better choice
- ETL Workloads; EMR and Glue is a better choice
- Not a replacement for RDBMS
- Querying across regions (unless you query a Glue Data Catalogue)
- Analytics and Visualization:
- Athena queries data sources that are registered with the AWS Glue Data Catalogue
- Running queries in Athena via the Data Catalogue uses the Data Catalogue schema to derive insight from the underlying dataset
- Usage:
-
Aurora
- MySQL and PostgreSQL - compatible
- faster than both
- up to 15 read replicas
- Continuous back up to S3
-
Opensearch
- Usage:
- Fully managed
- Analyze activity logs, social media sentiments, data stream updates from other AWS services
- Usage monitoring for mobile applications
- Integration:
- S3 buckets
- Kinesis Data streams
- DynamoDB streams
- CloudWatch/CloudTrail
- Zone Awareness
- Kinesis, DynamoDB, Logstash / Beats, and OpenSearch’s native API’s offer means to import data into Amazon OS
- Options:
- Dedicated master node
- Now, the master nodes are only used for the management of Opensearch domain that you’re creating, and it does not hold or process any data. You don’t need too many of them unless your cluster is really massive.
- Domains: An Amazon Opensearch service domain is a collection of all the resources needed to run the Opensearch cluster. it contains all the configuration for the cluster as a whole. A cluster in Amazon Opensearch parlance is a domain.
- Dedicated master node
- Cost:
- Opensearch instance hours
- EBS storage (if you choose this option), and standard data transfer fees
- Performance:
- Instance type, workload, index, number of shards used, read replicas, storage configurations
- Fast SSD instance storage for storing indexes or multiple EBS volumes
- Durability and Availability:
- Distributes domain instances across two different AZs
- Automated and manual snapshots for durability
- Scalability and Elasticity:
- Use API and CloudWatch metrics to automatically scale up/down
- Interfaces:
- S3, Kinesis, DynamoDB Streams, Kibana
- Lambda function as an event handler
- Anti-Patterns:
- OLTP; RDS better choice
- Ad hoc data querying, Athena is a better choice
- Opensearch is primarily for search and analytics.
- Usage:
-
QuickSight
- Usage:
- ad-hoc data exploration/visualization
- Dashboards and KPIs
- Analyze and visualize data coming from logs and stored in S3
- Analyze and visualize data in SaaS applications like Salesforce
- Cost:
- Standard: $9/user/month
- Enterprise: $18/user/month
- SPICE capacity for Standard
- Performance:
- SPICE uses a combination of columnar storage, in-memory technologies
- Machine code generation to run interactive queries on large datasets at low latency
- Durability and Availability:
- Automatically replicates data for high availability
- Scales to hundreds of thousands of users
- Simultaneous analytics across AWS data sources
- Scalability and Elasticity:
- Fully managed service, scale to terabytes of data
- Interfaces/Data Sources:
- RDS, Aurora, Redshift, Athena, S3
- SaaS, applications such as Salesforce
- Files (S3 or on-premises) such as Excel, CSV
- Anti-Patterns:
- Highly formatted canned Reports, better for ad hoc query, analysis, and visualization of data
- ETL; Glue is a better choice
- Capabilities:
- Need to know the capabilities and operational characteristics
- Data Source
- SPICE
- Superfast, parallel, in memory calculation engine
- Engineered to rapidly perform advanced calculations and serve data
- In the Enterprise edition, data in SPICE is encrypted at rest
- Can release unused SPICE capacity(in-memory data)
- Each user gets 10GB of SPICE
- Analysis
- Use analysis to create and interact with visuals and stories, a container for a set of related visuals and stories
- Use multiple data sets in an analysis, but any given visual can only use one data set
- Visuals
- Graphical representation of a data set using a diagram, chart, graph or table
- ML Insights
- ML Insights use machine learning to uncover hidden insights and trends in your data, identify key drivers, and forecast business metrics
- Quicksight Q allows NLP powered business questions
- Sheets
- Set of visuals that are viewed together in a single page(like excel)
- Dashboards
- Read-only snapshot of an analysis that you can share with other users for reporting
- Preserves the configuration of the analysis at the time of publishing
- When a user views the dashboard, it reflects the current data in the data sets used by the analysis
- Data Source
- Need to know the capabilities and operational characteristics
- Usage:
-
Analysis for Visualization
- Data Lake
- Lake Formation provides multi-service, fine-grained access control to data
- Macie helps detect sensitive data that may have been stored in the wrong place
- Inspector identifies configuration errors that could lead to data breaches
- Data Lake
-
-
Select the appropriate data analysis solution for a given scenario
-
Types of Analysis
- Descriptive Analysis (Data Mining)
- Determine what generated the data
- Lowest value
- Diagnostic Analysis
- Determine why data was generated
- Predictive Analysis
- Determine future outcomes
- Prescriptive Analysis
- Determine action to take
- Descriptive Analysis (Data Mining)
-
Analysis Solutions
- Batch Analytics
- Large volumes of raw data
- Analytics process on a schedule, reports
- EMR
- Interactive Analytics
- Complex queries on complex data at high speed
- See query results immediately
- Athena, Opensearch, Redshift
- Streaming Analytics
- Analysis of data that has short shelf-life
- Incrementally ingest data and update metrics
- Kinesis
- Batch Analytics
-
Analytics Solutions Patterns
- EMR
- Uses the map-reduce technique to reduce large processing problems into small jobs distributed across many nodes in a Hadoop cluster
- On demand big data analytics
- Event-driven ETL
- Machine Learning predictive analytics
- Clickstream analysis
- Load data warehouse
- Don’t use for transactional processing or with small data sets
- Uses the map-reduce technique to reduce large processing problems into small jobs distributed across many nodes in a Hadoop cluster
- Kinesis
- Streams data to analytics processing solutions
- Video analytics applications
- Real-time analytics applications
- Analyze IoT device data
- Blog posts and article analytics
- Streams data to analytics processing solutions
- Redshift
- OLAP using BI tools
- Near real-time analysis of millions of rows of manufacturing data generated by continuous manufacturing equipment
- Analyze events from mobile app to gain insight into how users use it
- Make live data generated by range of next-gen security solutions available to large numbers of organizations for analysis
- Don’t use OLTP or with small data sets
- OLAP using BI tools
- EMR
-
-
Select the appropriate data visualization solution for a given scenario
-
Refresh Schedule - Real time Scenarios
- Typically using Opensearch and Kibana
refresh_intervalin Opensearch domain updates the domain indices; determines query freshness- Default is every second
- Formula: K * (number of data nodes), where k is the number of shards per node
- Balance refresh rate cost with decision-making needs
- Typically using Opensearch and Kibana
-
Refresh Schedule - Interactive Scenarios
- Typically ad-hoc exploration using QuickSight
- Refresh Spice data
- Refresh a data set on a schedule, or you can refresh your data by refreshing the page in an analysis or dashboard
- Use the
CreateIngestionAPI operation to refresh data
- Data set based on a direct query and not stored in SPICE, refresh data by opening the data set
-
Refresh Schedule - EMR notebooks
- Use EMR notebooks to query and visualize data
- Data refreshed every time the notebook is run
-
QuickSight Visual Data - Filters
- QuickSight filter options for data interaction
- Filtering: used to focus on or exclude a visual element representing a particular value
- Associated with a single dataset in an analysis
- Scope to one, several, or all visuals in a dataset’s analysis
- Applies to only a single field, calculated or regular
- Make sure multiple filters applied to the same field aren’t mutually exclusive
- Filtering: used to focus on or exclude a visual element representing a particular value
- QuickSight filter options for data interaction
-
QuickSight Visual Data - Sorting
- QuickSight sorting options for data interaction
- Sorting: Most visual types offer the ability to change data sort order
- SPICE limitations for sort
- Up to two million unique values
- Up to 16 columns
- QuickSight sorting options for data interaction
-
QuickSight Visual Data - Drill Down
- QuickSight drill down options for data interaction
- Drill Down: All visual types except pivot tables allow creation of a hierarchy of fields for a visual element
- QuickSight drill down options for data interaction
-
Kibana - Visualization Tool
- Open source data visualization dn exploration tool used for log and time-series analytics, application monitoring, and operational intelligence use cases
- Histograms, line graphs, pie charts, heat maps, and built in geospatial support
- Tight integration with Opensearch
- Charts and reports to interactively navigate through large amounts of log data
- Pre-built aggregations and filters
- Dashboards and reports to sharer
-
Kibana - Configuration
- To visualize and explore data in Kibana, you must first create index patterns
- Index patterns point Kibana to the Opensearch indexes containing the data to explore
- Explore data with Kibana’s data discovery functions
- Kibana visualizations are based on Amazon Opensearch queries
-
Kibana - Security
- Cognito allows end-uers to log in to Kibana through enterprise identity providers such as Microsoft Active Directory using SAML
-
Visualization Use Case
Use Case Visualization Solution Equity trading managers need to drill into values in a visualization and perform ad- hoc queries on data that spans five days but is updated by the minute Browser access to an interactive report based on an Opensearch Kibana view A company's website shares previous years' sales volume by region, reports monthly revenue to the company, and highlights top performing regions Embed a QuickSight dashboard into the company's public web page that can be accessed via mobile platforms as well as browser Operations manager needs an end of week summary of operations research reports by region Send static report via email link to a location on an S3 bucket Data scientists need to visualize the results of machine learning models that use product data to predict potential supply chain issues based on the previous 6 months of data Use EMR Notebooks on EMR Security
-
-
Select appropriate authentication and authorization mechanisms
-
IAM Authentication
- To set permissions for an identity in IAM, choose an AWS managed policy, a customer managed policy, or an inline policy
- AWS managed policy
- Standalone policy that is created and administered by AWS
- Provide permissions for many common use cases
- Full
- Power-user
- Partial Access
- Use Case
- Best used when you are dealing with a service that has typical use cases that can be covered by AWS manged policy because it takes care of maintenance of the policy
- Customer Managed Policy
- Standalone policies that you administer in your AWS account
- Use Case
- When you have something that you would like to manage using AWS managed policy but you have your own customization that you would like to make
- Inline Policy
- Strict one-to-one relationship of policy to identity
- Policy embedded in an IAM identity (a user, group, or role)
- Use Case
- Very targeted policy on a specific user or group or a role that you can assign to a service such as Athena or S3
- Strict one-to-one relationship of policy to identity
- AWS managed policy
Services Action Resource level Permissions Resource Based Policies Auth Based on Tags Temp Creds Service-Linked Roles Athena ✅ ✅ ❌ ✅ ✅ ❌ Opensearch ✅ ✅ ✅ ❌ ✅ ✅ EMR ✅ ✅ ❌ ✅ ✅ ✅ Glue ✅ ✅ ✅ 🔶 ✅ ❌ Kinesis Analytics ✅ ✅ ❌ ✅ ✅ ❌ Kinesis Firehose ✅ ✅ ❌ ✅ ✅ ❌ Kinesis Streams ✅ ✅ ❌ ❌ ✅ ❌ Quicksight ✅ ✅ ❌ ✅ ✅ ❌ - ✅ = Yes
- ❌ = No
- 🔶 = Partial
-
IAM Authorization
- Use IAM identity and resource-based permission to authorize access to analytics resources
- Policy is an object in AWS you associate with an identity or resource to define the identity or resource permissions
- To use a permissions policy to restrict access to a resource you choose a policy type
- Identity based policy
- Attached to an IAM user, group, or role
- Specify what an identity can do (its permissions)
- Example: attach a policy to a user that allows that user to perform the EC2
RunInstancesaction
- Resource based policy
- Attached to a resource
- Specify which users have access to the resource and what actions they can perform on it
- Example: attach resource-based policies to S3 buckets, SQS queues, and Key Management Service encryption keys
- Identity based policy
- Control access/authorization using IAM policies
- Encryption in flight using HTTPS endpoints
- Encryption at rest using KMS
- Client side encryption must be manually implemented
- VPC Endpoints available for Kinesis to access within VPC
- To set permissions for an identity in IAM, choose an AWS managed policy, a customer managed policy, or an inline policy
-
Network Security
- Need to secure the physical boundary of your analytics services using network isolation
- Use VPC to achieve network isolation
- Example: EMR cluster where the master, core, and task nodes are in a private subnet using NAT to perform outbound only internet access
- Also, use security groups to control inbound and outbound access from your individual EC2 instances
- With EMR use both EMR-managed security groups and additional security groups to control network access to your instance
-
EMR - Managed Security Groups
- Every EMR cluster has managed security groups associated with it, either default or custom
- EMR automatically adds rules to managed security groups used by the cluster to communicate between cluster instances and AWS services
- Rules that EMR creates in managed security groups allow the cluster to communicate among internal components
- To allow users and applications to access a cluster from outside the cluster, edit rules in managed security groups
- Editing rules in managed security groups may have unintended consequences; may inadvertently block the traffic required for clusters to function properly
- Specify security groups only on cluster create, can’t add to a cluster or cluster instances while a cluster is running
- Can edit, add and remove rules from existing security groups, the rules take effect as soon as you save them
- There are two options
- Master node
- Cluster node (core node or task node)
-
EMR - Additional Security Groups
- Additional security groups are optional
- Specify in addition to manage security groups to tailor access to cluster instances
- Contain only rules that you define, EMR does not modify them
- To allow users and applications to access a cluster from outside the cluster, create additional security groups with additional rules
-
EMR - VPC Options - S3 Endpoints & NAT Gateway
- S3 Endpoints
- All instances in a cluster connect to S3 through either a VPC endpoint or internet gateway
- Create a private endpoint for S3 in your subnet to give your EMR cluster direct access to data in Amazon S3
- NAT Gateway
- Other AWS services which do not currently support VPC endpoints use only an internet gateway
- S3 Endpoints
-
Direct Connect (DX)
- Provides a dedicated private connection from a remote network to your VPC
- Dedicated connection must be setup between your DC and AWS Direct Connection locations
- You need to set up a Virtual Private Gateway on your VPC
- Access public resources (S3) and private (EC2) on same connection
- Use Cases:
- Increase bandwidth throughput - working with large data sets - lower costs
- More consistent network experience - application using real-time data feeds
- Hybrid environments (on prem + cloud)
- Supports both IPv4 and IPv6
- Connection Types:
- Dedicated Connections: 1 GB/sec, 10GB/sec
- Physical ethernet port dedicated to a customer
- Hosted Connections: 50 MB/sec, 500 MB/sec, 10GB/sec
- Capacity can be added or removed on demand
- Encryption
- Data in transit is not encrypted but is private
- Direct Connect + VPN provides an IPsec-encrypted private connection
- Resiliency
- High resiliency for critical workloads - consists of a second separate backup connection
- Maximum resiliency for critical workloads - each direct location has to two independent locations (total 4)
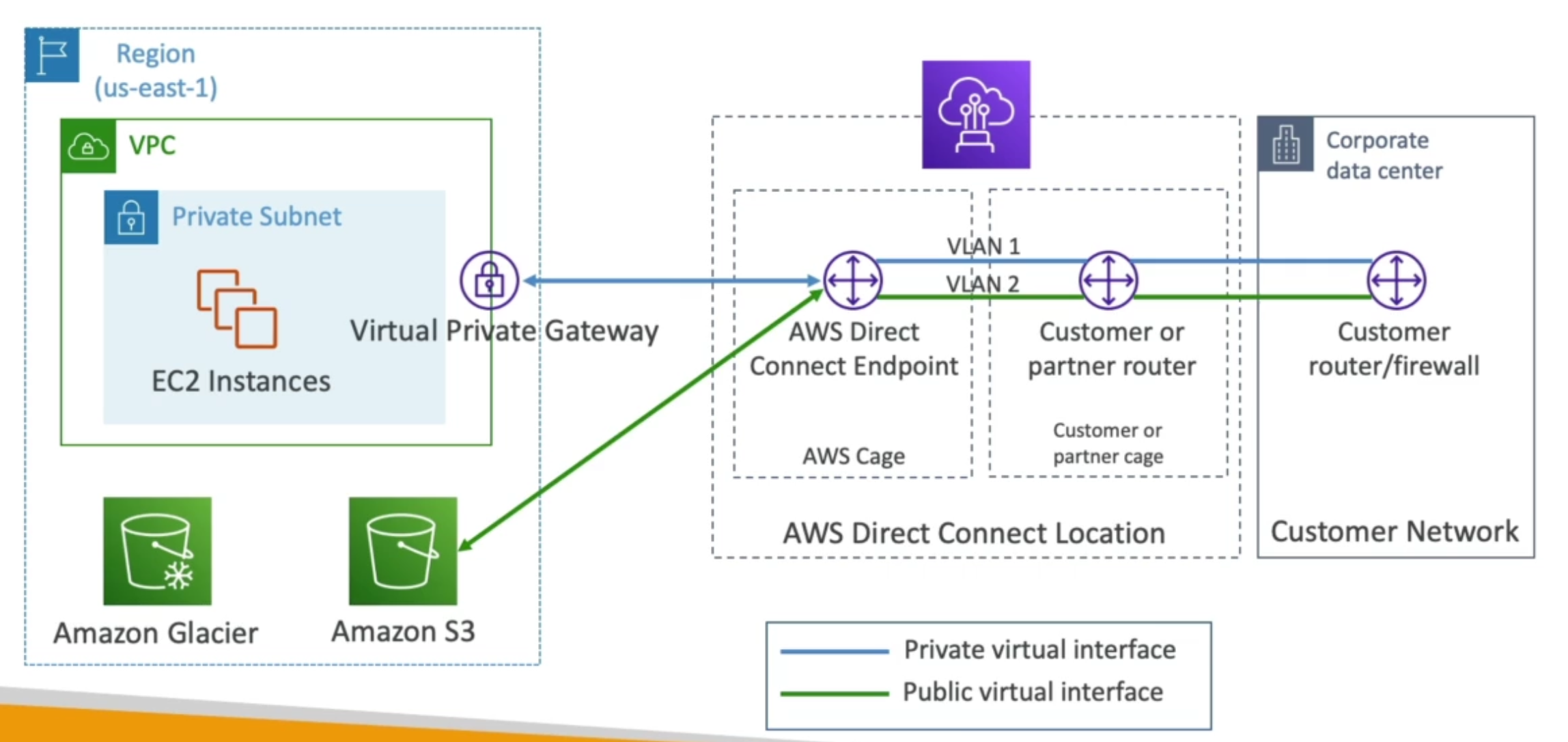
- Dedicated Connections: 1 GB/sec, 10GB/sec
-
QuickSight Security
- VPC connectivity
- Add QuickSight’s IP address range to your database security groups
- Row level/Column level security
- Enterprise edition only
- Private VPC access
- Quicksight + Redshift
- By default, Quicksight can only access data stored in the same region as the one quicksight is running within
- If you have QuickSight in one region, and Redshift in another, that won’t work
- Solution: Create a new security group with an inbound rule authorizing access from the IP range of QuickSight servers in that region
- VPC connectivity
-
Kinesis Security
- Kinesis Data Streams
- SSL endpoints using the HTTPS protocol to do encryption in flight
- AWS KMS provides server-side encryption (encryption at rest)
- For client side encryption, you must use your own encryptoin libraries
- Supported interface VPC Endpoints / Private Link
- KCL - must get read/write access to DynamoDB table (it uses it for checkpointing)
- Kinesis Data Firehose
- Attach IAM roles so it can deliver to S3 / OS / Redshift / Splunk
- Can encrypt the delivery stream with KMS (server-side encryption)
- Supported interface VPC Endpoints / Private Link
- Kinesis Data Analytics
- Attach IAM role so it can read from Kinesis Data Streams and reference sources and write to an output destination (ex. Kinesis Data Firehose)
- Kinesis Data Streams
-
SQS Security
- IAM policy must allow usage of SQS
- SQS queue access policy
-
S3 Security
- IAM policies
- S3 bucket policies
- Access Control Lists (ACLs)
- Encryption at flight using HTTPS
- Encryption at rest
- Versioning + MFA delete
- CORS for protecting websites
- VPC Endpoint is provided through a Gateway
- Glacier - vault lock policies to prevent deletes (WORM)
-
RDS/Aurora Security
- VPC provides network isolation
- Security Groups control network access to DB instances
- KMS provides encryption at rest
- SSL provides encryption in-flight
- Must manage user permissions within the database itself
-
Lambda Security
- IAM roles attach to each Lambda function
- Lambda will pull data from sources and will send data to targets. The IAM roles attached to your Lambda functions will help you decide what your lead the function can do in terms of sources and targets
-
Glue Security
- Configure Glue to only access JDBC through SSL
- Data Catalogue
- Encrypted by KMS
- Resource policies to protect Data Catalog resources
- Connection password: encrypted by KMS
- Data written by Glue can be encrypted
-
QuickSight Security
- Standard edition
- IAM users
- Email based accounts
- Enterprise edition
- Active Directory
- Federated Login
- Supports MFA
- Encryption at rest and in SPICE
- row level security
- Standard edition
-
Security Token Service (STS)
- Allows the granting of limited and temporary access to AWS resources
- Token valid for up to one hour (must be refreshed)
- Usage
- Cross account access
- Federation (active directory)
- Provides a non-AWS user with temporary AWS access by linking users Active Directory
- Uses SAML
- Allows SSO
- Federation with third party providers / Cognito
- Used mainly in web and mobile applications
- Makes use of Facebook/Google/Amazon etc. to federate them
-
Identity Federation
- Federation lets users outside of AWS to assume a temporary role for accessing AWS resources
- These users assume identity provided access role
- Federation assumes a form of 3rd party authentication
- LDAP
- Microsoft Active Directory (SAML)
- Single Sign On
- Open ID
- Cognito
- SAML Federation for Enterprises
- To integrate Active Directory / ADFS with AWS
- Provides access to AWS Console or CLI (through temporary credentials)
- No need to create an IAM user for each of your employees
- Custom Identity Broker Application for Enterprises
- Use only if identity provider is not compatible with SAML 2.0
- The identity broker must determine the appropriate IAM policy
- Cognito
- Provides direct access to AWS resources from the client side
-
-
Apply data protection and encryption techniques
-
Encryption and Tokenization
- Protect data against data exfiltration (unauthorized copying and/or transferring data) and unauthorized access
- Different ways to protect data
- Use a hardware security module (HSM) to manage the top-level encryption keys
- Use HSM if you require your keys to be stored in a dedicated, third-party validated hardware security modules under your exclusive control
- If you need to comply with FIPS 140-2
- If you need high-performance in-VPC cryptographic acceleration
- If you need a multi-tenant, managed service that allows you to use and manage encryption keys
- Encryption at rest & transit
- Prevent unauthorized users from reading data on a cluster and associated data storage systems
- Alternative to encryption to secure highly sensitive subsets of data for compliance purposes
- Secrets management
- Use secrets in application code to connect to databases, API, and other resources
- Provides rotation, audit, and access control
- Systems Manager Parameter Store
- Centralized store to manage configuration data
- Plain-text data such as database strings or secrets such as passwords
- Does not rotate parameter stores automatically
- Use a hardware security module (HSM) to manage the top-level encryption keys
-
Types of Encryption
- SSE-S3
- Keys are handled and managed by Amazon
- Object is encrypted server side
- AES-256 encryption type
- SSE-KMS
- Keys are handled and managed by KMS
- KMS advantage: user control + audit trail
- Object is encrypted server side
- SSE-C
- Server-side encryption using data keys fully managed by the customer outside of AWS
- Amazon S3 does not store the encryption key you provide
- HTTPS must be used
- Client Side Encryption
- You encrypt/decrypt the object yourself before uploading
- SSE-S3
-
Key Management Service (KMS)
- Easy way to control access to your data, AWS manages keys and encryption
- Fully integrated with IAM
- The value in KMS is that the CMK used to encrypt data can never be retrived by the user
- types of CMK
- AWS managed service default CMK
- User keys created in KMS
- User keys imported
- Automatic Key Rotation
- For Customer managed CMK
- if enabled, key rotation happens every 1 year
- Previous key is kept active so you can decrypt old data
- New key has the same CMK ID (only the backing key is changed)
- Manual Key Rotation
- New key has a different CMK ID
-
CloudHSM
- AWS provisions dedicated physical encryption hardware
- You manage your own encryption keys entirely
- HSM device is tamper resistant
-
EMR Encryption
- At rest data encryption for EMRFS
- Encryption in S3
- SSE-S3, SSE-KMS, Client Side encryption
- Encryption in Local Disks
- Encryption in S3
- At rest data encryption for local disks
- Open source HDFS encryption
- EC2 instance store encryption
- NVMe encryption or LUKS encryption (physically)
- EBS Volumes
- EBS encryption (KMS) - works with root volume
- LUKS encryption - does not work with root
- In transit encryption
- Node to node communication
- for EMRFS traffic between S3 and cluster nodes
- TLS encryption
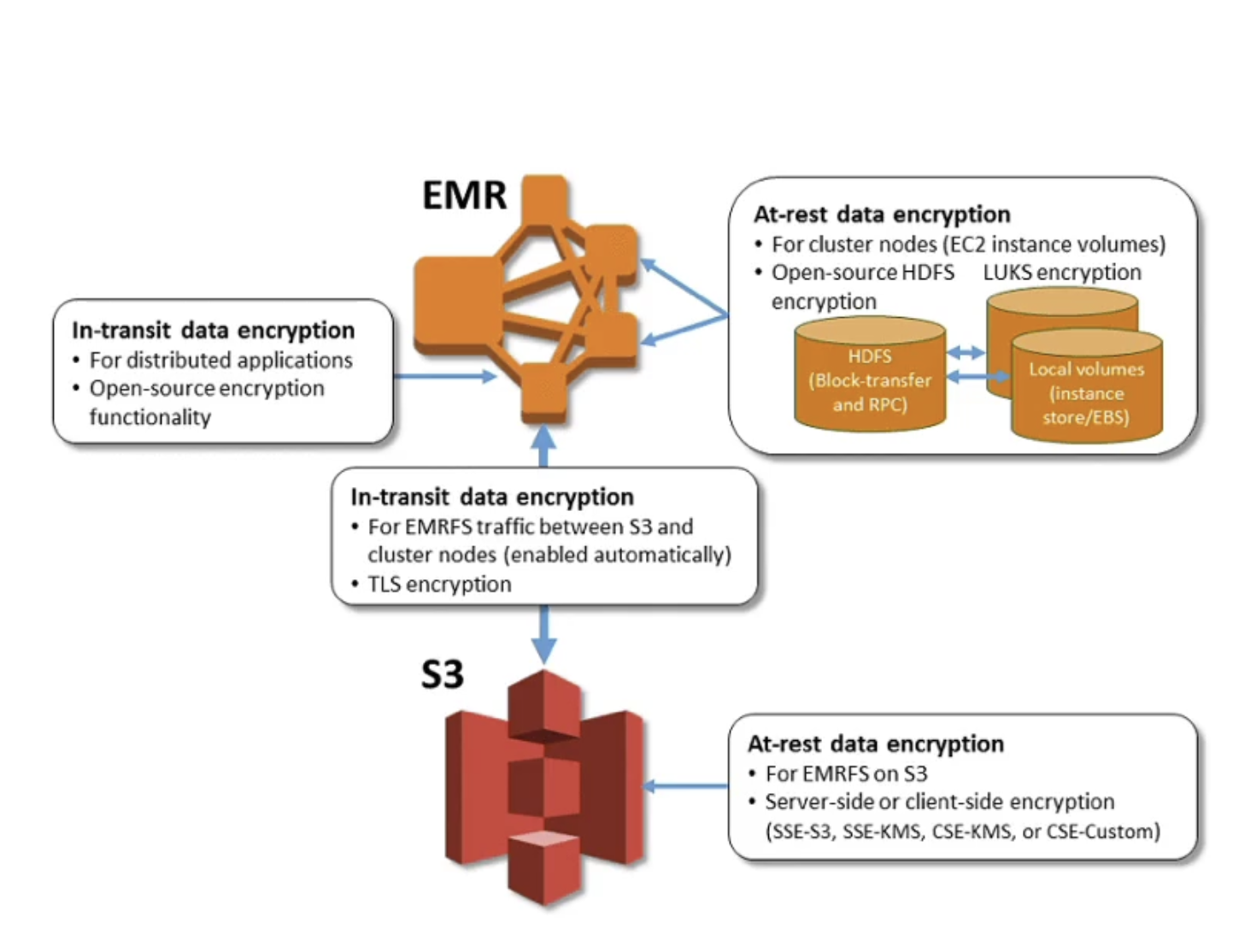
- At rest data encryption for EMRFS
-
VPC Endpoints
- Endpoints allow you to connect to AWS Services using a private network instead of the public ‘www’ network
- SQS is a public service you can access it from your local computer. It is accessible on the worldwide web but say you wanted to access it from within an EC2 instance on a private subnet. One way would be to give internet access to that EC2 instance but that would be a bit tricky because you need to create a public subnet, you need a new gateway all that stuff or you can just create a VPC endpoint also called private link which basically has a private connection directly into the SQS service and then to connect to the SQS service. Simple as that your EC2 instance will connect directly into the VPC end point
- Gateway Endpoint
- Provisions a target must be used in a route table - only S3 and DynamoDB
- Interface (VPC PrivateLink)
- Provisions an ENI (private IP address) as an entry point (must attach security group) - most AWS services
-
-
Apply data governance and compliance controls
-
Compliance and Governance
- Identify required compliance frameworks (HIPAA, PIC, etc.)
- Understand contractual and agreement obligations
- Monitor policies, standards, and security controls to respond to events and changes in risk
- Services to create compliant analytics solution
- AWS Artifact
- Provides on-demand access to AWS compliance and security related information
- self-service document retrieval portal
- Manage AWS agreements
- Provide security controls documentation
- Download AWS security and compliance documents
- CloudTrail and CloudWatch
- Enable governance, compliance, operational auditing, and risk auditing of AWS account
- CloudTrail tracks actions in your AWS account by recording API activity
- CloudWatch monitors how resources perform, collecting application metrics, and log information
- Simplify security analysis, resource change tracking, and troubleshooting by combining event history via CloudWatch
- Use CloudTrail to audit and review API calls and detect security anomalies
- Use CloudWatch to create alert rules that trigger SNS notifications to a security or risk event
- If a resource is deleted in AWS, look into CloudTrail first
- Only shows 90 days past of activity
- CloudTrail Trails allow you to get a detailed list of all the events you choose
- AWS Config
- Ensure AWS resources conform to your organization’s security guidelines and best practices
- AWS resource inventory, configuration history, and configuration change notifications that enable security and governance
- Logs in CloudWatch
- Discover existing AWS resources
- Export complete inventory of account AWS resources with all configuration details
- Determine how a resource was configured at any point in time
- Config Rules: represent desired configuration for a resource and is evaluated against configuration changes on the relevant resources, as recorded by AWS Config
- Assess overall compliance and risk status from a configuration perspective, view compliance trends over time and pinpoint which configuration change caused by a resource to drift out of compliance with a rule
- AWS Artifact
-
-
AWS Service Integrations
-
Kinesis Streams - Producers
-
Kinesis Streams - Consumers
-
Kinesis Firehose - Sources
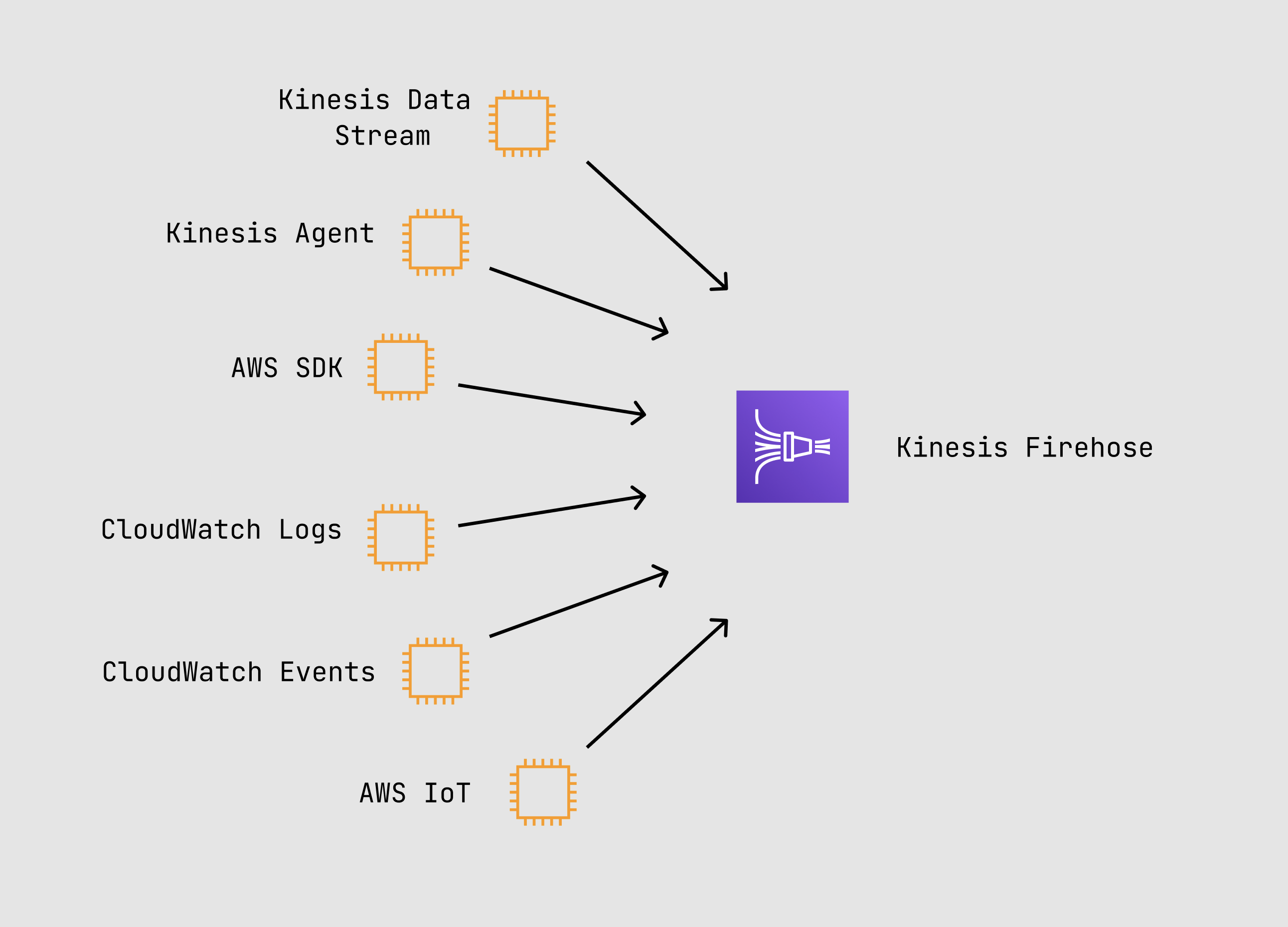
-
Kinesis Firehose - Destinations
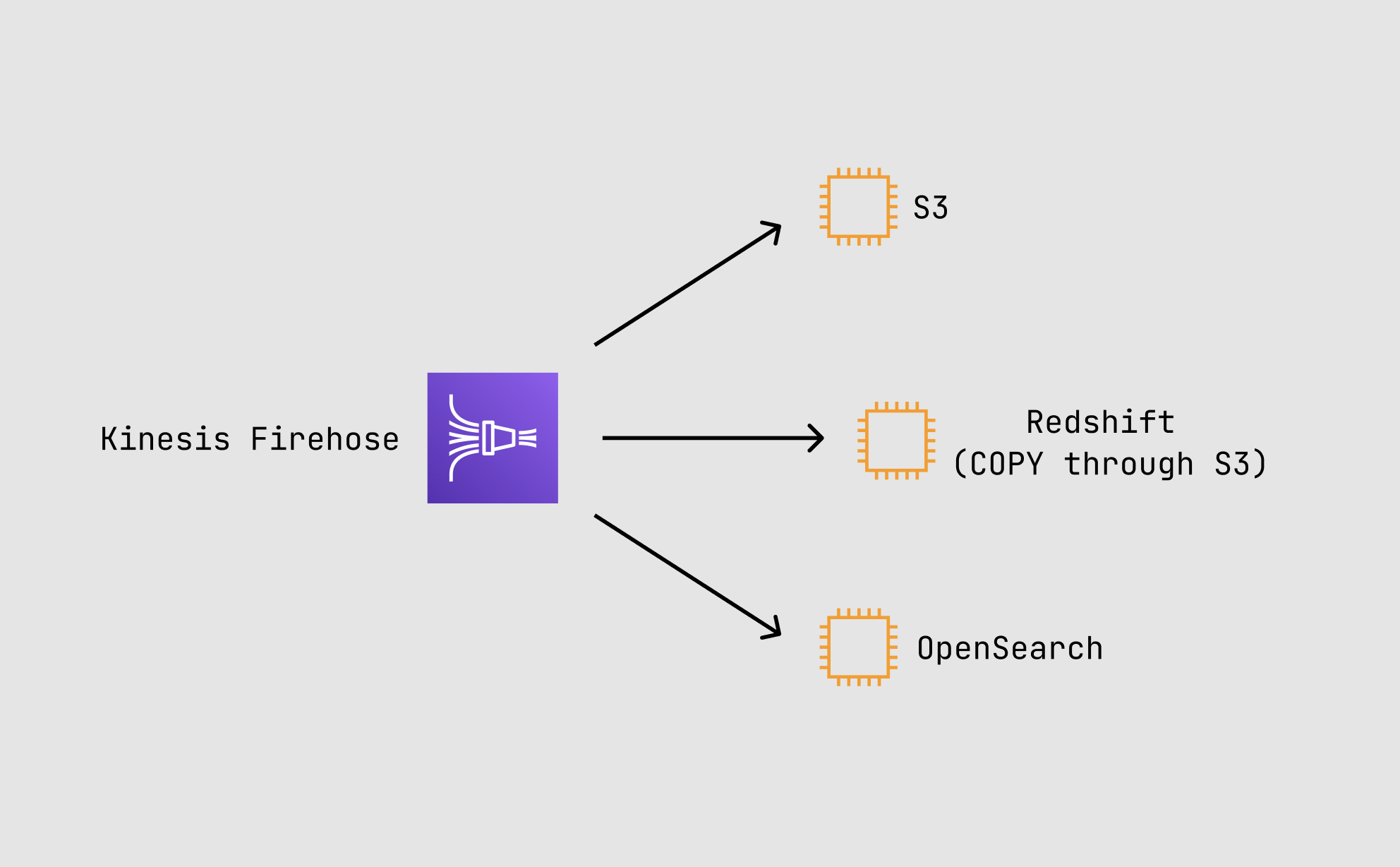
-
Kinesis Data Analytics - Sources
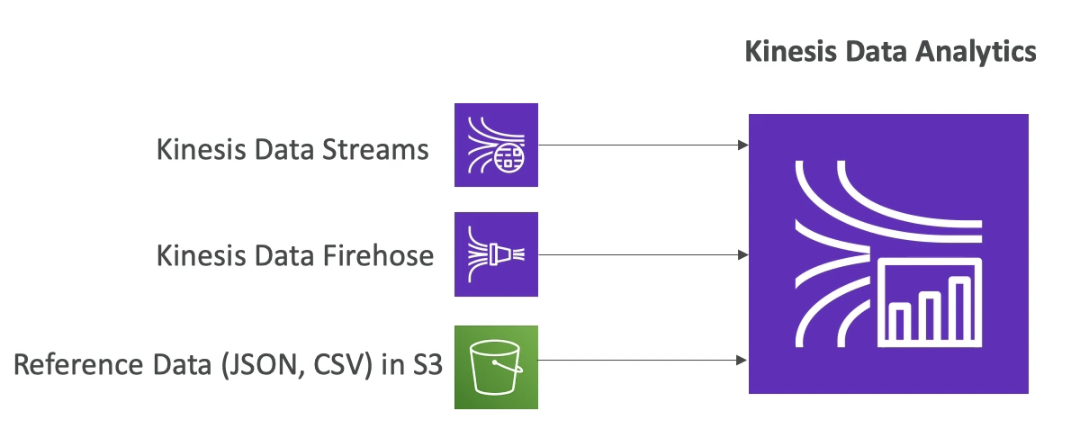
-
Kinesis Data Analytics - Destinations
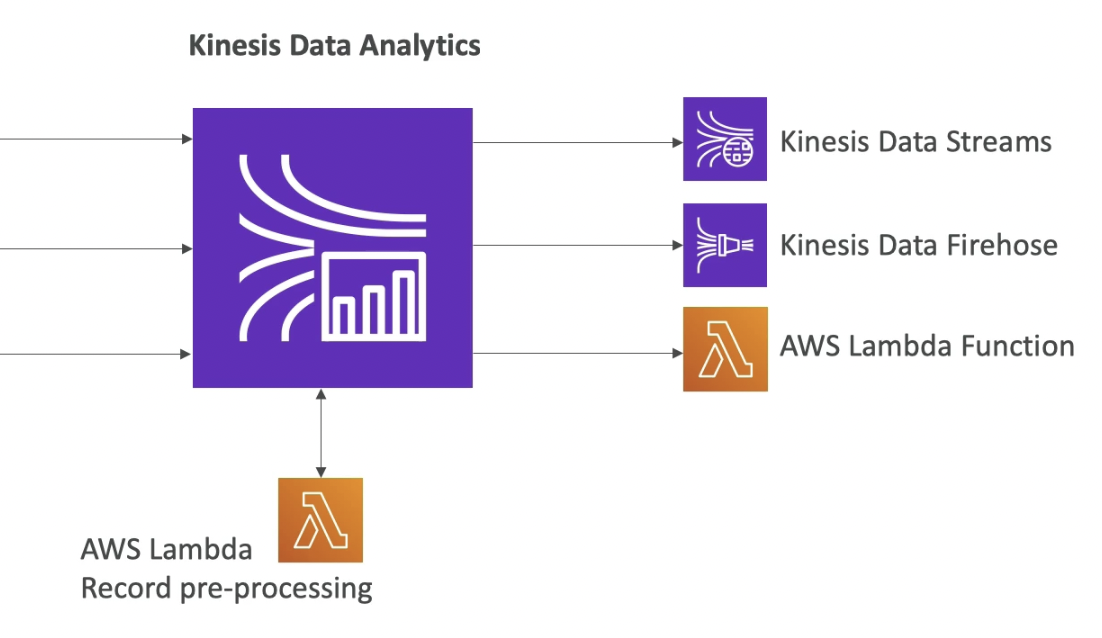
-
SQS - Destinations and Sources
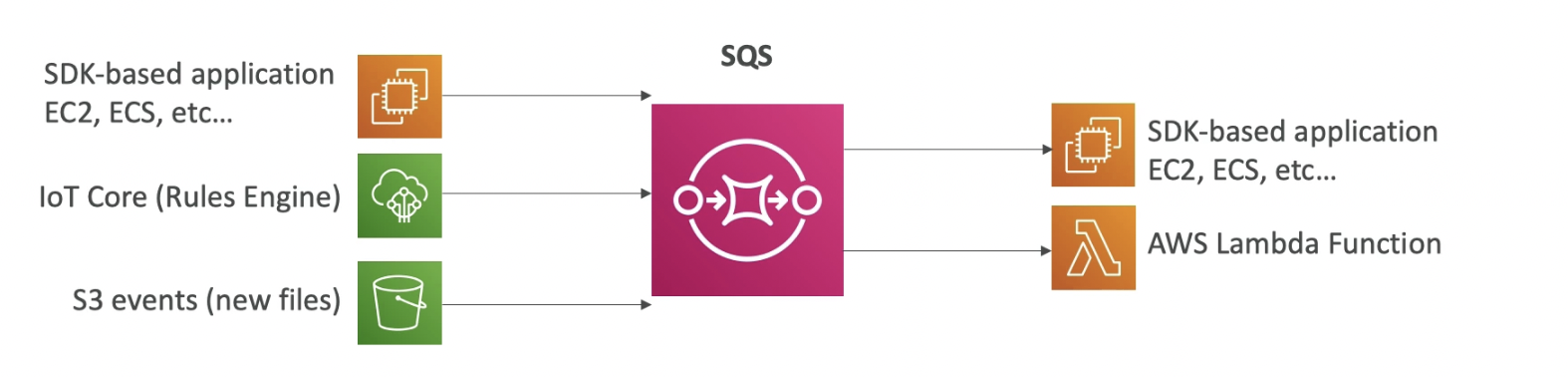
-
DynamoDB - Destinations and Sources
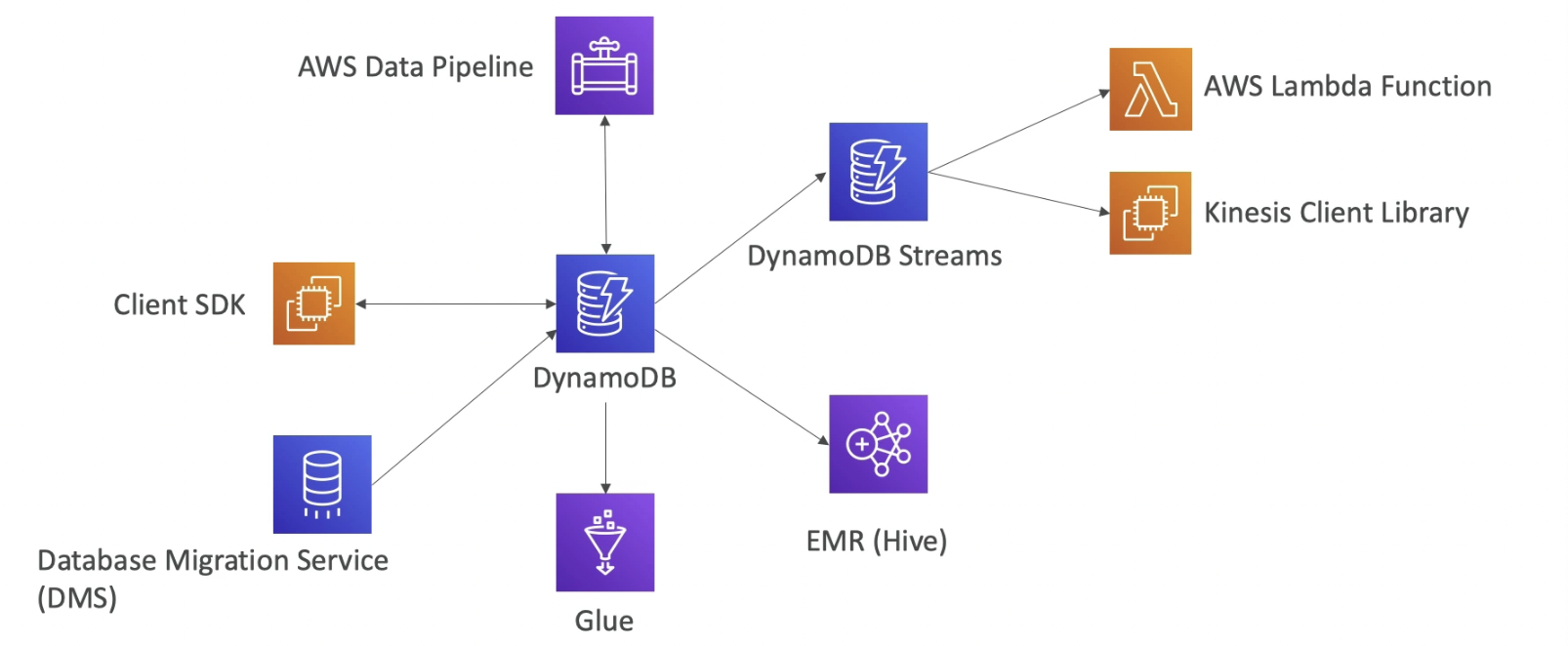
-
OpenSearch - Sources
-
Athena - Destinations and Sources
-
-
Notes
- The entire security in DynamoDB is managed through IAM, we don’t need to create users within DynamoDB
- Amazon EMR supports multiple master nodes to enable high availability for EMR applications. Launch an EMR cluster with three master nodes and support high availability applications like YARN Resource Manager, HDFS Name Node, Spark, Hive, and Ganglia. EMR clusters with multiple master nodes are not tolerant of Availability Zone failures. In the case of an Availability Zone outage, you lose access to the EMR cluster.
- Archive objects that are queried by S3 Glacier Select must be formatted as uncompressed comma-separated values (CSV).
- Duplicate records in Kinesis can be the result of a network-related timeout or a change in the number of shards
ExpiredIteratorExceptions: If the shard iterator expires immediately, before you can use it, this might indicate that the DynamoDB table used by Kinesis does not have enough capacity to store the lease data. This situation is more likely to happen if you have a large number of shards. To solve this problem, increase the write capacity units assigned to the shard table- A large number of small files in S3 will slow down reads from Athena, but splitting a large file will help loading to Redshift in performance. Having one large file will load in serialized manner which lowers performance
- Kinesis Data Streams records are available to be read immediately after they are written. There are some use cases that need to take advantage of this and require consuming data from the stream as soon as it is available. You can significantly reduce the propagation delay by overriding the KCL default settings to poll more frequently, as shown in the following examples
MSCK REPAIR TABLE: compares the partitions in the table metadata and the partitions in S3. If new partitions are present in the S3 location that you specified when you created the table, it adds those partitions to the metadata and to the Athena table- Amazon S3 buckets can support 3,500
PUT/COPY/POST/DELETEor 5,500GET/HEADrequests per second per partitioned prefix. Every partition prefix gets additional support and that is why it is wise to add a prefix especially when there is a large set of data - Amazon Machine Image (AMI): Provides the information required to launch an instance
- You can create a custom AMI with encrypted root device volumes
- Access Control Lists (ACLs) provide important authorization controls Apache Kafka clusters data.
- Use a heat map if you want to identify trends and outliers, because the use of color makes these easier to spot
- How does Lake Formation organize my data in a data lake? You can use one of the blueprints available in Lake Formation to ingest data into your data lake. Lake Formation creates Glue workflows that crawl source tables, extract the data, and load it to S3. In S3, Lake Formation organizes the data for you, setting up partitions and data formats for optimized performance and cost. For data already in Amazon S3, you can register those buckets with Lake Formation to manage them.
- Athena Federated Query: if you have data in sources other than Amazon S3, you can use Athena Federated Query to query the data in place or build pipelines that extract data from multiple data sources and store them in Amazon S3. With Athena Federated Query, you can run SQL queries across data stored in relational, non-relational, object, and custom data sources
- Redshift Federated Query: By using federated queries in Amazon Redshift, you can query and analyze data across operational databases, data warehouses, and data lakes. With the Federated Query feature, you can integrate queries from Amazon Redshift on live data in external databases with queries across your Amazon Redshift and Amazon S3 environments. Federated queries can work with external databases in Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon Aurora MySQL-Compatible Edition. You can use federated queries to incorporate live data as part of your business intelligence (BI) and reporting applications. For example, to make data ingestion to Amazon Redshift easier you can use federated queries to do the following:
- Query operational databases directly
- Apply transformations quickly
- Load data into the target tables without the need for complex extract, transform, load (ETL) pipelines
- AVRO stores data in row format and does not compress the data. However, Parquet is a columnar store (without any additional compression algorithm like snappy applied), it natively compresses the data by 2X to 5X on average
- AWS Elastic Resize vs. Classic Resize:
- Amazon Redshift allows you to migrate to a certain number of nodes during a cluster resize. By default, Amazon Redshift aims to maintain the same number of slices in the target cluster
- Elastic resize – Use elastic resize to change the node type, number of nodes, or both. If you only change the number of nodes, then queries are temporarily paused and connections are held open if possible. During the resize operation, the cluster is read-only. Typically, elastic resize takes 10–15 minutes. AWS recommends using elastic resize when possible
- Classic resize – Use classic resize to change the node type, number of nodes, or both. Choose this option when you are resizing to a configuration that isn’t available through elastic resize. An example is to or from a single-node cluster. During the resize operation, the cluster is read-only. Typically, classic resize takes 2 hours–2 days or longer, depending on your data’s size
- Note:
- Elastic resize often require less time to complete than a classic resize. When you resize a cluster in Amazon Redshift using elastic resize (without changing the node type), Amazon Redshift automatically redistributes data to the new nodes. Unlike classic resize (which provisions a new cluster and transfers data to it), elastic resize doesn’t create a new cluster. Elastic resize typically completes within a few minutes. You can expect a small increase in your query execution time while elastic resize completes data redistribution in the background.
- Amazon Redshift supports access control at a column-level for data in Redshift. Customers can use column-level grant and revoke statements to help them meet their security and compliance needs. Ex.
grant select(cust_name, cust_phone) on cust_profile to user1;
- Athena per-query control limit vs. per-workgroup limit data usage control limit
- Athena allows you to set two types of cost controls: per-query limit and per-workgroup limit. For each workgroup, you can set only one per-query limit and multiple per-workgroup limits.
- The per-query control limit specifies the total amount of data scanned per query. If any query that runs in the workgroup exceeds the limit, it is canceled. You can create only one per-query control limit in a workgroup and it applies to each query that runs in it
- The workgroup-wide data usage control limit specifies the total amount of data scanned for all queries that run in this workgroup during the specified time period. You can create multiple limits per workgroup. The workgroup-wide query limit allows you to set multiple thresholds on hourly or daily aggregates on data scanned by queries running in the workgroup.
- Locking is a protection mechanism that controls how many sessions can access a table at the same time. Locking also determines which operations can be performed in those sessions. Most relational databases use row-level locks. However, Amazon Redshift uses table-level locks. You might experience locking conflicts if you perform frequent DDL statements on user tables or DML queries
- QuickSight can use Random Cut Forest
- AWS Glue ETL job
groupFilesis supported for DynamicFrames created from the following data formats: csv, ion, grokLog, json, and xml. This option is not supported for avro, parquet, and orc - Instance Groups vs. Instance Fleets
- Instance Groups
- Manually add instances of the same type to existing core and task instance groups
- Manually add a task instance group, which can use a different instance type
- Set up automatic scaling in Amazon EMR for an instance group, adding and removing instances automatically based on the value of an Amazon CloudWatch metric that you specify. For more information, see Scaling cluster resources
- Instance Fleets
- Add a single task instance fleet
- Change the target capacity for On-Demand and Spot Instances for existing core and task instance fleets. For more information, see Configure instance fleets
- Instance Groups
YARNMemoryAvailablePercentage: the percentage of remaining memory available to YARN. This value is useful for scaling cluster resources based on YARN memory usageCapacityRemainingGB: The amount of remaining HDFS disk capacity. Use case: Monitor cluster progress, Monitor cluster health- AWS Glue crawler minimum schedule is 5 minutes
- Background vacuum operations on AWS Redshift might be blocked if materialized views aren’t refreshed
- QuickSight connects only to data located in the same AWS Region where you’re currently using QuickSight. You can’t connect QuickSight to data in another AWS Region, even if your VPC is configured to work across AWS Regions. The solution is to create a new security group for with an inbound rule authorizing access from the appropriate IP address range for the Amazon QuickSight servers in ap-northeast-1
- Database audit logging : Amazon Redshift logs information about connections and user activities in your database. These logs help you to monitor the database for security and troubleshooting purposes, a process called database auditing. The logs are stored in Amazon S3 buckets. These provide convenient access with data-security features for users who are responsible for monitoring activities in the database. The connection log, user log, and user activity log are enabled together by using the AWS Management Console, the Amazon Redshift API Reference, or the AWS Command Line Interface (AWS CLI)
- In the Enterprise edition of Amazon QuickSight, you can restrict access to a dataset by configuring row-level security (RLS) on it. You can do this before or after you have shared the dataset. When you share a dataset with RLS with dataset owners, they can still see all the data. When you share it with readers, however, they can only see the data restricted by the permission dataset rules. By adding row-level security, you can further control their access
- The service role for cluster EC2 instances (also called the EC2 instance profile for Amazon EMR) is a special type of service role that is assigned to every EC2 instance in an Amazon EMR cluster when the instance launches. Application processes that run on top of the Hadoop ecosystem assume this role for permissions to interact with other AWS services
- QuickSight does not support S3 files with parquet format, Athena does
- An EMR cluster can reside only in one Availability Zone or subnet
- AWS Encryption SDK
- The AWS Encryption SDK is a client-side encryption library designed to make it easy for everyone to encrypt and decrypt data using industry standards and best practices. It enables you to focus on the core functionality of your application, rather than on how to best encrypt and decrypt your data
- When you see “key that can be rotated” it must be CMK, You cannot rotate key that you did not create
- AWS Glue allows you to consolidate multiple files per Spark task using the file grouping feature. Grouping files together reduces the memory footprint on the Spark driver as well as simplifying file split orchestration. Without grouping, a Spark application must process each file using a different Spark task. Spark applications processing more than roughly 650,000 files often cause the Spark driver to crash with an out of memory exception
- High JVM memory pressure on OpenSearch Service cluster
- Spikes in the numbers of requests to the cluster
- Aggregations, wildcards, and selecting wide time ranges in the queries
- Unbalanced shard allocations across nodes or too many shards in a cluster
- Field data or index mapping explosions
- Instance types that can’t handle incoming loads
- AWS Glue can crawl data in different AWS Regions. When you define an Amazon S3 data store to crawl, you can choose whether to crawl a path in your account or another account
- To successfully connect Amazon QuickSight to the Amazon S3 buckets used by Athena, make sure that you authorized Amazon QuickSight to access the S3 account. It’s not enough that you, the user, are authorized. Amazon QuickSight must be authorized separately
- Which components must be included in each Redshif query monitoring rule?
- Each rule includes up to three conditions, or predicates, and one action
- Kinesis Data Firehose can only have one destination per stream (Kinesis Data Streams can have multiple)
- AWS Data Exchange makes it easy to find, subscribe to, and use third-party data in the cloud
- Redshift
COPYcommand- Amazon Redshift can automatically load in parallel from multiple compressed data files. However, if you use multiple concurrent COPY commands to load one table from multiple files, Amazon Redshift is forced to perform a serialized load
- You can use a manifest to ensure that your COPY command loads all of the required files, and only the required files, from Amazon S3. You can also use a manifest when you need to load multiple files from different buckets or files that don’t share the same prefix
- Lambda maximum running time 15 minutes
- EMR - Block public access is only applicable during cluster creation by choosing the
Block public accesssetting - Kinesis Data Analytics uses Random Cut Forest ML
- AWS Glue can exclude certain S3 storage types using the
excludeStorageClassesproperty - Anything EMR comparing to serverless Glue / Athena is operational overhead. Also remember Glue can do PySpark and Scala, and Athena can do JDBC
- When it comes to high-performance and high write throughput to KDS, KPL should be choice
- You might want to create AWS Glue Data Catalog tables manually and then keep them updated with AWS Glue crawlers. Crawlers running on a schedule can add new partitions and update the tables with any schema changes. This also applies to tables migrated from an Apache Hive metastore
- Redshift workload management query queue hopping only works for manual WLM config
- With the Redshift Concurrency Scaling feature, you can support virtually unlimited concurrent users and concurrent queries, with consistently fast query performance. When you turn on concurrency scaling, Amazon Redshift automatically adds additional cluster capacity to process an increase in both read and write queries
- EMRFS consistent view tracks consistency using a DynamoDB table to track objects in Amazon S3 that have been synced with or created by EMRFS
- Kinesis Data Firehose: Do not Need lambda to convert from JSON to Parquet, it is a built-in capability
- AWS DataSync is a secure, online service that automates and accelerates moving data between on premises and AWS storage services. DataSync can copy data between Network File System (NFS) shares, Server Message Block (SMB) shares, Hadoop Distributed File Systems (HDFS), self-managed object storage, AWS Snowcone, Amazon Simple Storage Service (Amazon S3) buckets, Amazon Elastic File System (Amazon EFS) file systems, Amazon FSx for Windows File Server file systems, and Amazon FSx for Lustre file systems
- Amazon DynamoDB Time to Live (TTL) allows you to define a per-item timestamp to determine when an item is no longer needed. Shortly after the date and time of the specified timestamp, DynamoDB deletes the item from your table without consuming any write throughput. TTL is provided at no extra cost as a means to reduce stored data volumes by retaining only the items that remain current for your workload’s needs
- Redshift supports two types of sort keys:
- Compound Sort Key (Default): The compound sort key is a key composed of one or more columns. The order of the columns in the sort key is crucial as they define how the actual data gets stored on the disk. As a best practice, you should order the col- umns in the lowest to highest cardinality. These are effective when a majority of the queries on a table filter or join are on a specific subset of columns
- Interleaved Sort Key: Each column in the sort key is sorted with equal weighting. This is useful when multiple queries use different access paths and different columns for filters and joins. This should be used with caution and edge cases only
- CloudWatch Logs subscription
- You can use subscriptions to get access to a real-time feed of log events from CloudWatch Logs and have it delivered to other services such as an Amazon Kinesis stream, an Amazon Kinesis Data Firehose stream, or AWS Lambda for custom processing, analysis, or loading to other systems. When log events are sent to the receiving service, they are base64 encoded and compressed with the gzip format
- To begin subscribing to log events, create the receiving resource, such as a Kinesis stream, where the events will be delivered. A subscription filter defines the filter pattern to use for filtering which log events get delivered to your AWS resource, as well as information about where to send matching log events to
- As a best practice, AWS strongly recommends that you create a service role for cluster EC2 instances and permissions policy so that it has the minimum permissions to other AWS services that your application requires
- S3DistCp
- Apache DistCp is an open-source tool you can use to copy large amounts of data. S3DistCp is similar to DistCp, but optimized to work with AWS, particularly Amazon S3. The command for S3DistCp in Amazon EMR version 4.0 and later is s3-dist-cp, which you add as a step in a cluster or at the command line. Using S3DistCp, you can efficiently copy large amounts of data from Amazon S3 into HDFS where it can be processed by subsequent steps in your Amazon EMR cluster. You can also use S3DistCp to copy data between Amazon S3 buckets or from HDFS to Amazon S3. S3DistCp is more scalable and efficient for parallel copying large numbers of objects across buckets and across AWS accounts.
- AWS Lambda can perform data enrichment like looking up data from a DynamoDB table, and then produce the enriched data onto another stream. Lambda is commonly used for preprocessing the analytics app to handle more complicated data formats.
- Identity-based policies vs. resource-based policies
- Identity-based policies are attached to an IAM user, group, or role. These policies let you specify what that identity can do (its permissions). For example, you can attach the policy to the IAM user named John, stating that he is allowed to perform the Amazon EC2 RunInstances action. The policy could further state that John is allowed to get items from an Amazon DynamoDB table named MyCompany. You can also allow John to manage his own IAM security credentials. Identity-based policies can be managed or inline
- Resource-based policies are attached to a resource. For example, you can attach resource-based policies to Amazon S3 buckets, Amazon SQS queues, VPC endpoints, and AWS Key Management Service encryption keys. For a list of services that support resource-based policies, see AWS services that work with IAM
- Identity-based policies and resource-based policies are both permissions policies and are evaluated together. For a request to which only permissions policies apply, AWS first checks all policies for a Deny. If one exists, then the request is denied. Then AWS checks for each Allow. If at least one policy statement allows the action in the request, the request is allowed. It doesn’t matter whether the Allow is in the identity-based policy or the resource-based policy
- External Metastore for Hive
- By default, Hive records metastore information in a MySQL database on the master node’s file system. The metastore contains a description of the table and the underlying data on which it is built, including the partition names, data types, and so on. When a cluster terminates, all cluster nodes shut down, including the master node. When this happens, local data is lost because node file systems use ephemeral storage. If you need the metastore to persist, you must create an external metastore that exists outside the cluster.
- You have two options for an external metastore:
- AWS Glue Data Catalog (Amazon EMR version 5.8.0 or later only)
- Using Amazon EMR version 5.8.0 or later, you can configure Hive to use the AWS Glue Data Catalog as its metastore. This configuration is recommended when you require a persistent metastore or a metastore shared by different clusters, services, applications, or AWS accounts
- Amazon RDS or Amazon Aurora
- To use an external MySQL database or Amazon Aurora as your Hive metastore, you override the default configuration values for the metastore in Hive to specify the external database location, either on an Amazon RDS MySQL instance or an Amazon Aurora PostgreSQLinstance
- AWS Glue Data Catalog (Amazon EMR version 5.8.0 or later only)
- You have two options for an external metastore:
- By default, Hive records metastore information in a MySQL database on the master node’s file system. The metastore contains a description of the table and the underlying data on which it is built, including the partition names, data types, and so on. When a cluster terminates, all cluster nodes shut down, including the master node. When this happens, local data is lost because node file systems use ephemeral storage. If you need the metastore to persist, you must create an external metastore that exists outside the cluster.
- AWS Glue can crawl data in different AWS Regions. The output of the crawler is one or more metadata tables defined in the AWS Glue Data Catalog
- Kinesis Data Analytics Query Types
- Stagger Windows: A query that aggregates data using keyed time-based windows that open as data arrives. The keys allow for multiple overlapping windows. It is suited for analyzing groups of data that arrive at inconsistent times. This is the recommended way to aggregate data using time-based windows, because Stagger Windows reduce late or out-of-order data compared to Tumbling windows
- Tumbling Windows: A query that aggregates data using distinct time-based windows that open and close at regular intervals
- Sliding Windows: A query that aggregates data continuously, using a fixed time or rowcount interval.
- For Amazon QuickSight to access your AWS resources, you must create security groups for them that authorize connections from the IP address ranges used by Amazon QuickSight servers. You must have AWS credentials that permit you to access these AWS resources to modify their security groups. For Amazon QuickSight to connect to an Amazon Redshift instance, you must create a new security group for that instance. This security group contains an inbound rule authorizing access from the appropriate IP address range for the Amazon QuickSight servers in that AWS Region
- With Amazon EMR you can encrypt log files stored in Amazon S3 with an AWS KMS customer-managed key. Logging needs to be enabled when you launch the cluster.
- S3 Resource-Based Policies
- ACL: Each bucket and object have an associated ACL, which is basically a list of grants identifying the permission granted and to whom it is being granted. ACLs can be used to provide basic read/write permissions to other AWS accounts and use an AWS S3–specific XML schema
- Bucket Policy: Bucket policy is a JSON document that grants other AWS accounts or IAM users permissions to the buckets and objects contained in the bucket. Bucket policies supplement and in some cases replace the ACL policies. The following is an example of bucket policy
- A single Kinesis data stream is capable of collecting data from multiple different data sources
Once you pass, you’ll earn the beautiful badge below!
![]() AWS DAS Badge
AWS DAS Badge